Lab 7: One-Way ANOVA
One-Way ANOVA
In undergrad courses, you may have learned that ANOVA is used when your DV is continuous and your IV is categorical. Let’s say that our DV is average SAT Math score across schools, SAT_Math. We think that the school’s borough, borough, will have some impact on SAT_Math. In other words, we think that the means of SAT_Math (DV), will be change depedning on borough (IV). To put it simply (and probably too simply):
SAT_Math, if there are mean differences depedning on borough, we conclude that borough is associated with SAT_Math.
Starting from the Top
ANOVA stands for analysis of variance. The whole idea of ANOVA goes back to the idea of variance explained that we discussed in lab 6.
We have our dependent variable, SAT_Math, which is the average SAT math score across all New York public schools. (kinda skewed!)
As we talked about in the Lab 6, if we were trying to predict SAT_Math for any NYC public school and this plot on the right is all the information we have, our best guess would be the mean of SAT_Math.
Plot Code
ggplot(dat, aes(x = SAT_Math)) +
geom_density() +
geom_vline(xintercept = mean(dat$SAT_Math, na.rm = TRUE), lty = 3) +
annotate("text", x = 510, y = 0.007, label = paste(mean(dat$SAT_Math, na.rm = TRUE), ", the mean of \n the SAT_Math variable"), size = 7) +
scale_y_continuous(expand = c(0,0)) +
theme(
axis.title.y = element_blank(),
axis.text.y = element_blank(),
axis.ticks.y = element_blank(),
axis.line.y = element_blank())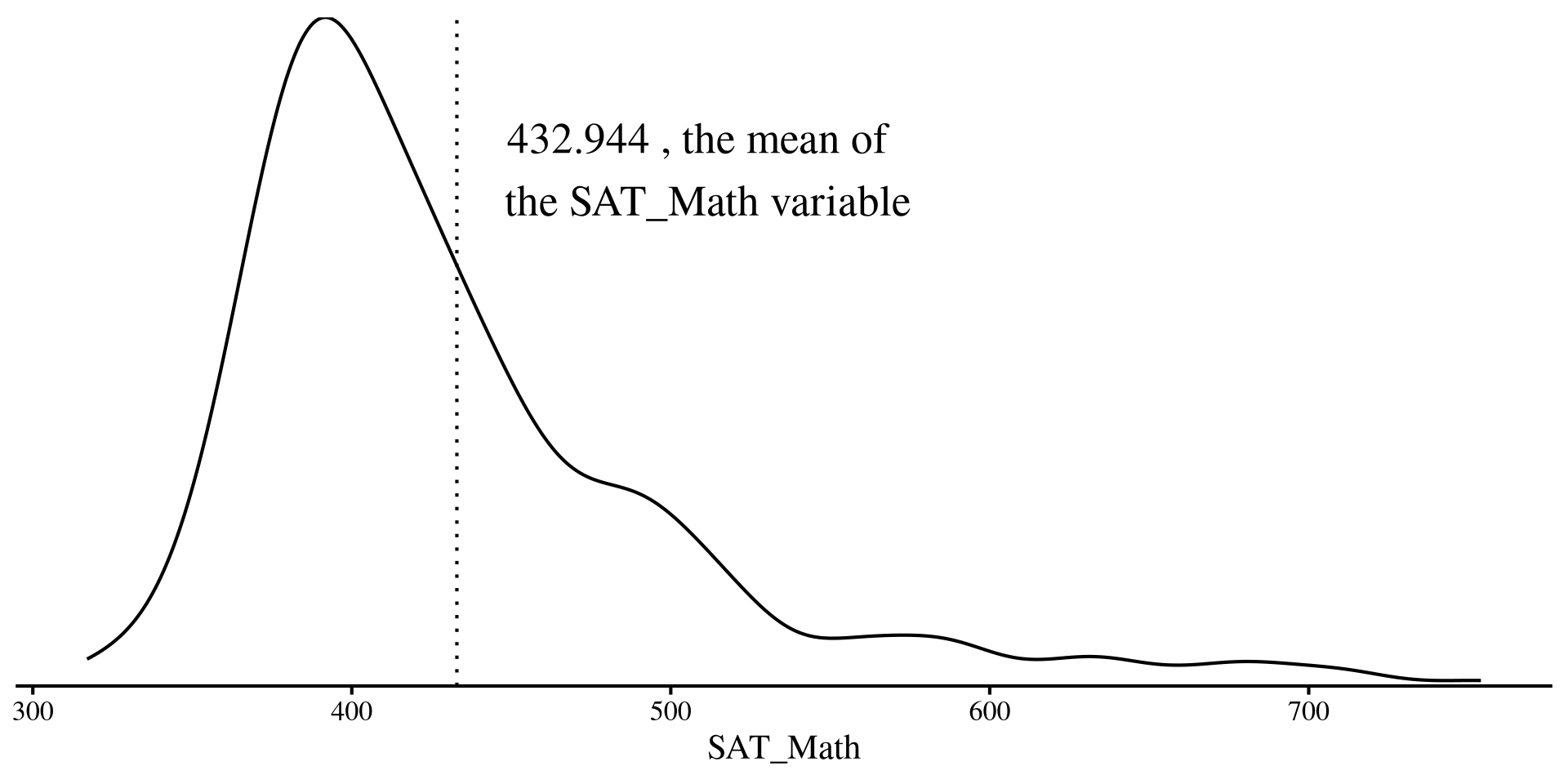
Residual Variance with only one Mean
Here I plot the residuals for the SAT_Math variable if all we know is the mean of SAT_Math.
The residual variance is just the variance of the the SAT_Math variable:
var(dat$SAT_Math, na.rm = TRUE)[1] 5177.144na.rm = TRUE?
Function like mean(), sd() and so on have this argument called na.rm =. The argument is used when you have missing data in the column you want to run functions on. na.rm = TRUE tells the function to run the function on complete cases only. Why? Because you should tell software what to do when missing values are encountered.
Plot Code
# some arbitrary monotonically increasing values to plot the residuals
dat$mono_incr <- 1:nrow(dat)
ggplot(dat, aes(x = mono_incr, y = SAT_Math)) +
geom_point() +
geom_hline(yintercept = mean(dat$SAT_Math, na.rm = TRUE), col = "#7a0b80") +
# geom_segment(y = 0, yend = dat$SAT_Math - mean(dat$SAT_Math, na.rm = TRUE), lty = 3, col = "red") +
theme(
axis.title.x = element_blank(),
axis.text.x = element_blank(),
axis.ticks.x = element_blank(),
axis.line.x = element_blank())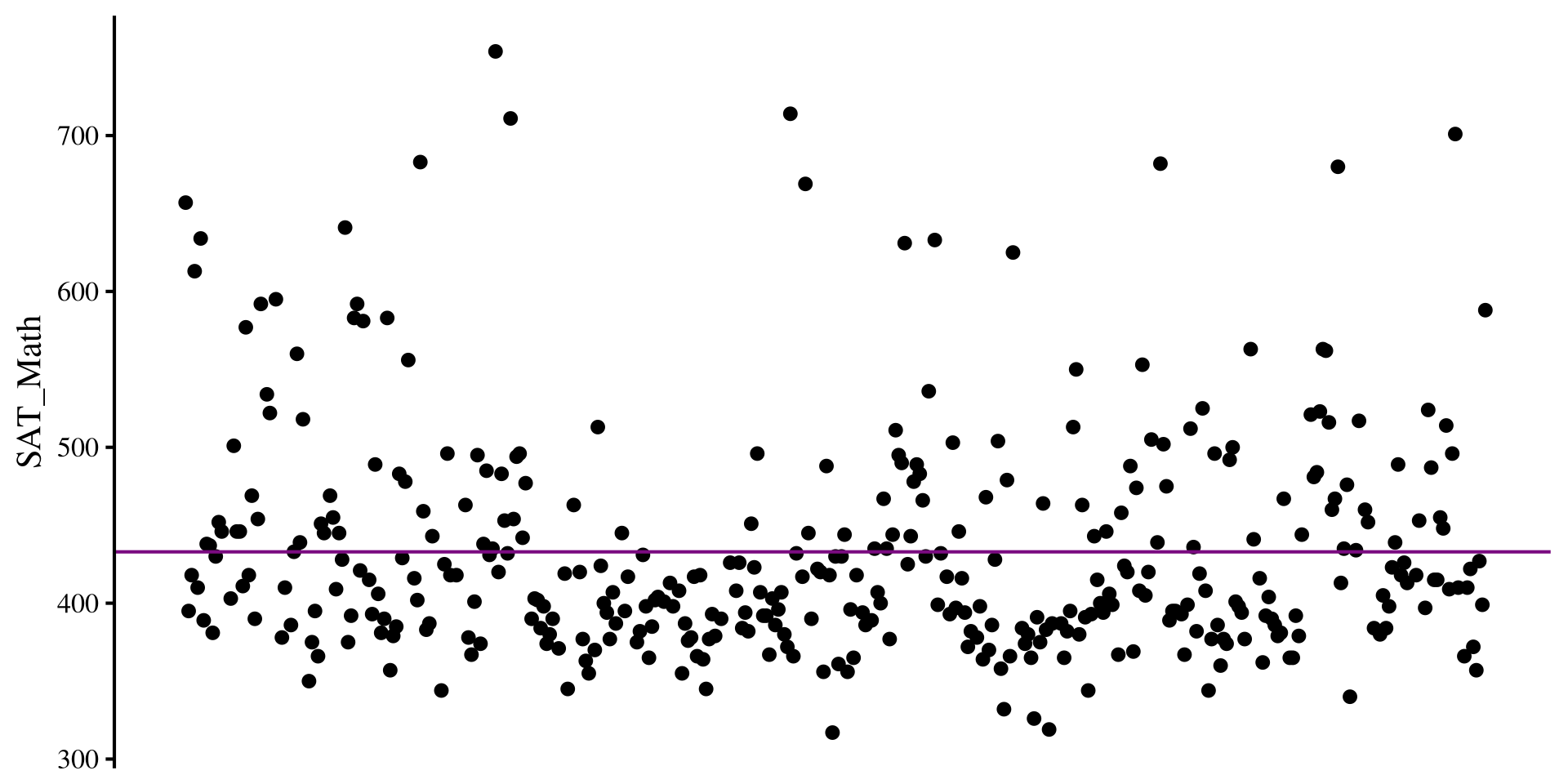
Multiple Means
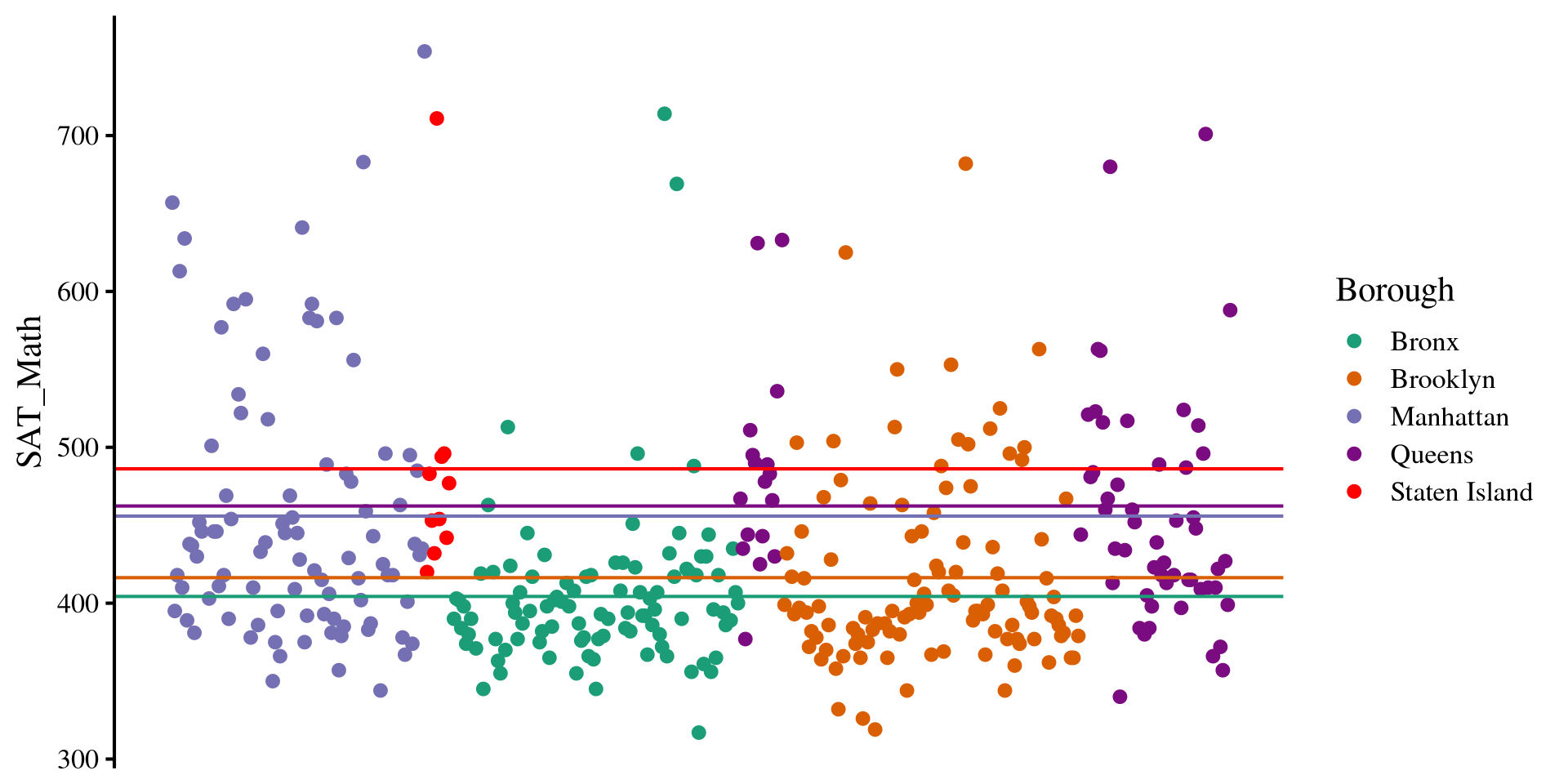
However, we think that there are going to be differences in SAT_Math scores across different New York boroughs, the Borough variable in the data.
Instead of the mean of SAT_Math as our best guess, we use the mean of SAT_Math by each of the Borough of New York!
dat %>%
group_by(Borough) %>%
summarise(mean = mean(SAT_Math, na.rm = TRUE))# A tibble: 5 × 2
Borough mean
<chr> <dbl>
1 Bronx 404.
2 Brooklyn 416.
3 Manhattan 456.
4 Queens 462.
5 Staten Island 486.Plot Code
sum_mean <- dat %>%
group_by(Borough) %>%
summarise(mean = mean(SAT_Math, na.rm = TRUE))
ggplot(dat, aes(x = mono_incr, y = SAT_Math, color = Borough)) +
geom_point() +
# queens
geom_hline(yintercept = as.numeric(sum_mean[4,2]), col = "#7a0b80") +
# Brooklyn
geom_hline(yintercept = as.numeric(sum_mean[2,2]), col = "#d95f02") +
# Bronx
geom_hline(yintercept = as.numeric(sum_mean[1,2]), col = "#1b9e77") +
# Manhattan
geom_hline(yintercept = as.numeric(sum_mean[3,2]), col = "#7570b3") +
# queens
geom_hline(yintercept = as.numeric(sum_mean[5,2]), col = "red") +
scale_color_manual(values = c(
"#1b9e77", # green
"#d95f02", # orange
"#7570b3", # purple
"#7a0b80", # dark purple
"red" # olive/green
)) +
theme(
axis.title.x = element_blank(),
axis.text.x = element_blank(),
axis.ticks.x = element_blank(),
axis.line.x = element_blank()
)
Assumptions: Residuals Once again?
Because ANOVA is a regression, it has one main assumption, which is that the residuals are normally distributed as in this Lab 6 slide 🧐
The catch is that our “regression lines” are now the individual group means, and the residuals are the distance of every school SAT_Math score from their group mean.
This is equivalent to saying that we want the groups to be normally distributed around their group mean 😀 Plotting a distribution by Borough is equivalent to checking that the residuls are normally distributed 🤯
Plot Code
ggplot(dat, aes(x = SAT_Math)) +
geom_density()+
facet_wrap(~Borough, scales = "free")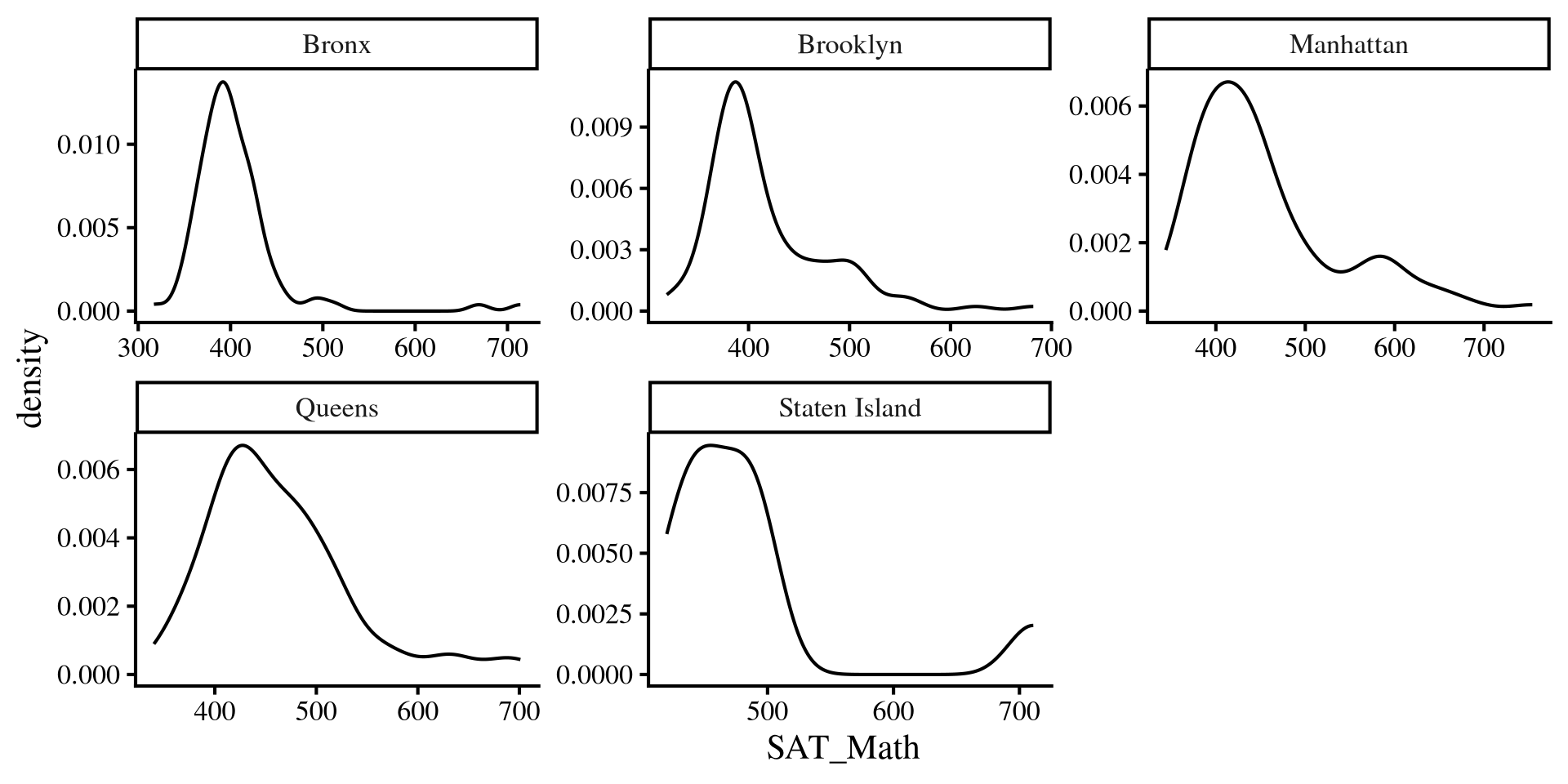
Normality Assumption: Violin Plots
ggplot(dat, aes(y = SAT_Math,
x = Borough,
fill = Borough)) +
geom_violin() +
# this will create a boxplot inside the violins
geom_boxplot(width = 0.1)Violin plots are very helpful visualizations because they can provide a lot of information:
- For each borough, the outside part is a density plot and shows the variable distribution (it’s mirrored)
- For each borough, we have a boxplot inside the density, which shows median, IQR, and outliers.
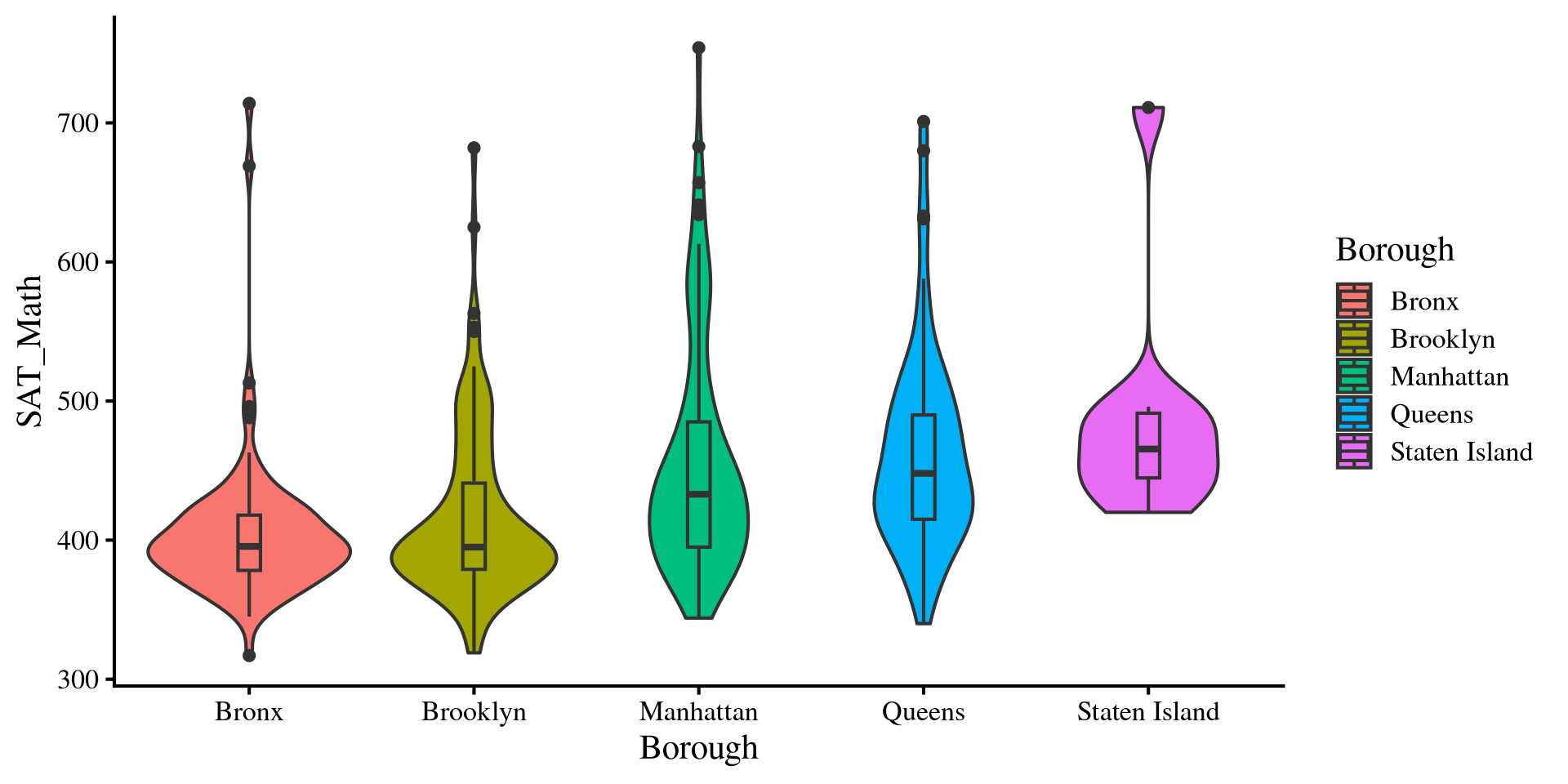
So, we get A LOT of information about the group distributions in a single plot. Notably, we can see that we have some outliers that skew our distributions. These are schools that score very high on SAT_Math
Equal variances Assumptions: Violin Plots
normal ANOVAs also assume that the variance is equal across groups. Just like the t-test, the assumption of equal variances rarely holds in practice.
We can see that the desnities have different shapes, suggesting differences in group variances. We can also look at the range of the histograms and see that the height of the rectagnle is different across groups.
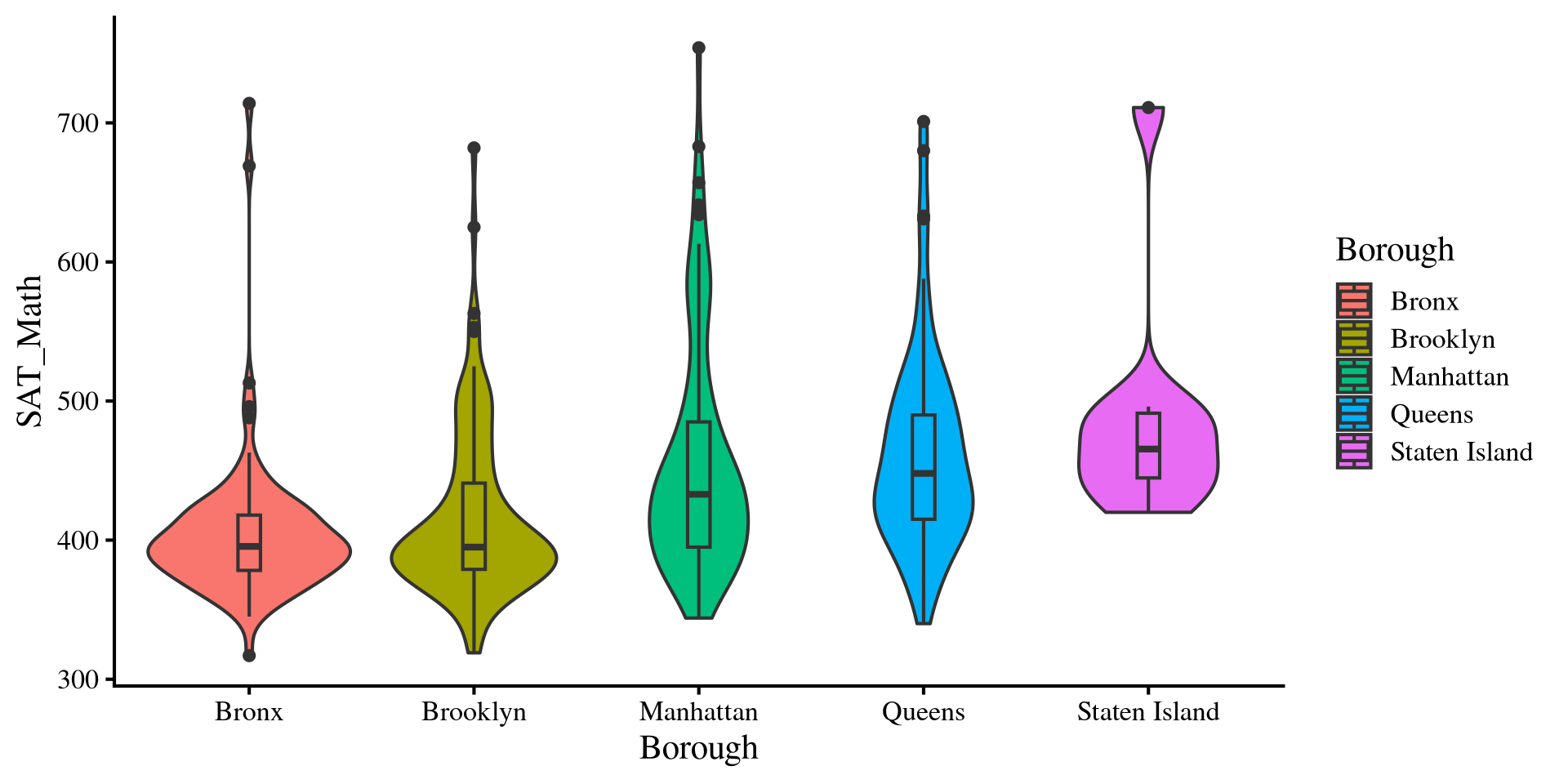
We will look at some adjustments to the ANOVA results when assumptions are violated. However, note that we will only look at adjustments to the ANOVA itself, not to all the other analyses such as mean comparisons and contrasts.