Lab 2: Descriptive Statistics, Data Manipulation, and Plotting
Data Manipulation with dplyr
![]()
Data Visualization with ggplot2
![]()
Working With ggplot2
I use ggplot2 a lot, but I can’t say that I would be able to create any plot “off the top of my head”. There are many ggplot2 functions, so learning what all of them do is impossible. When using ggplot2, I recommend that you:
-
Try to understand the logic behind
ggplot2’s syntax. - Start with a simple plot and progressively build upon it.
- Read functions documentation (i.e., function help menu) when something does not work as expected.
- Look things up. Usually I start with some plot code that I find online that produces a similar plot to what I want, and then I modify/build on top of it.
GGplot fact that you did not ask for
ggplot2 is an implementation of Leland Wilkinson’s Grammar of Graphics, a scheme that breaks down data visualization into its components (e.g, lines, axes, layers…)

The Canvas
As mentioned in the box on the last slide, ggplot2 breaks visualizations into small parts and pastes them on top of each other through the + operator.
ggplot() Just running ggplot() actually gives output! This is our “canvas”
(You cannot see anything because the output is a white square, but it’s there, I promise 😅)

Define Coordinates with aes()
We use the aes() function to defined coordinates. Note that the name of the data object (WH_2024 in our case) is almost always the first argument of the ggplot() function. Let’s define the axes and put Social_support on the x-axis and Happiness_score on the y-axis.
ggplot(WH_2024,
aes(x = Social_support,
y = Happiness_score)) 
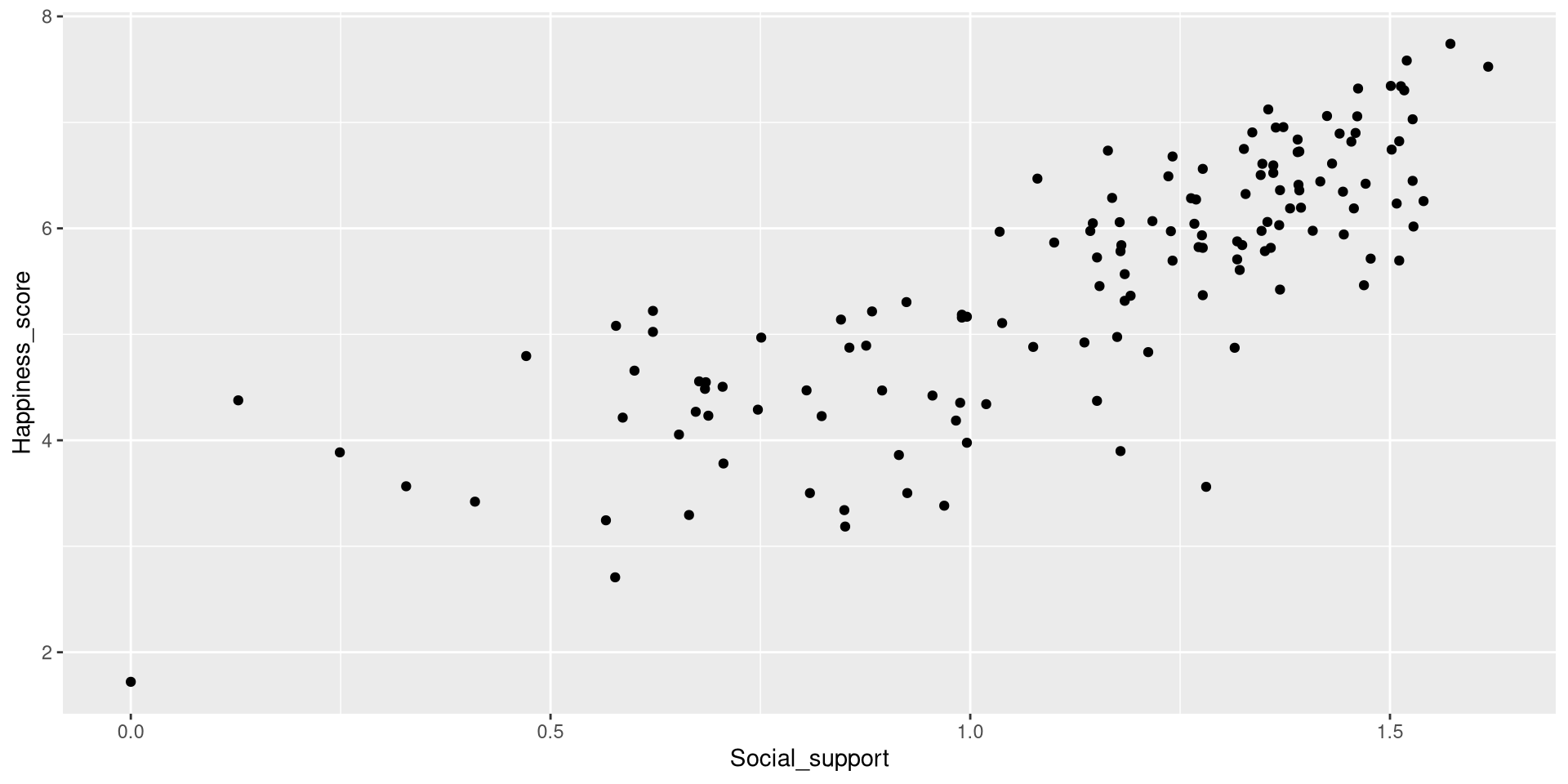
Scatterplot
We use one of the geom_...() functions to add shapes to our plot. This is a the geom_point() function can be use to create scatterplots.
ggplot(WH_2024,
aes(x = Social_support,
y = Happiness_score)) +
geom_point()geom_...()
The geom_...() functions add geometrical elements to a blank plot (see here for a list of all the geom_...() functions). Note that most geom_...() will inherit the X and Y coordinates from the ones given to the aes() function in the ggplot() function.
Themes
Sometimes ggplot2’s default theme is not the best (not sure what changed but it should look much worse than what I have on the slides) . There are many themes you can choose from, I like theme_classic().
ggplot(WH_2024,
aes(x = Social_support,
y = Happiness_score)) +
geom_point() +
theme_classic()Set plots theme globally
You can also use the theme_set() that will set a default theme for all the plots that you create afterwards. So, in our case, we could run theme_set(theme_classic()), and the theme_classic() function would be applied to all the following plots, without needing to specify + theme_classic() every time.
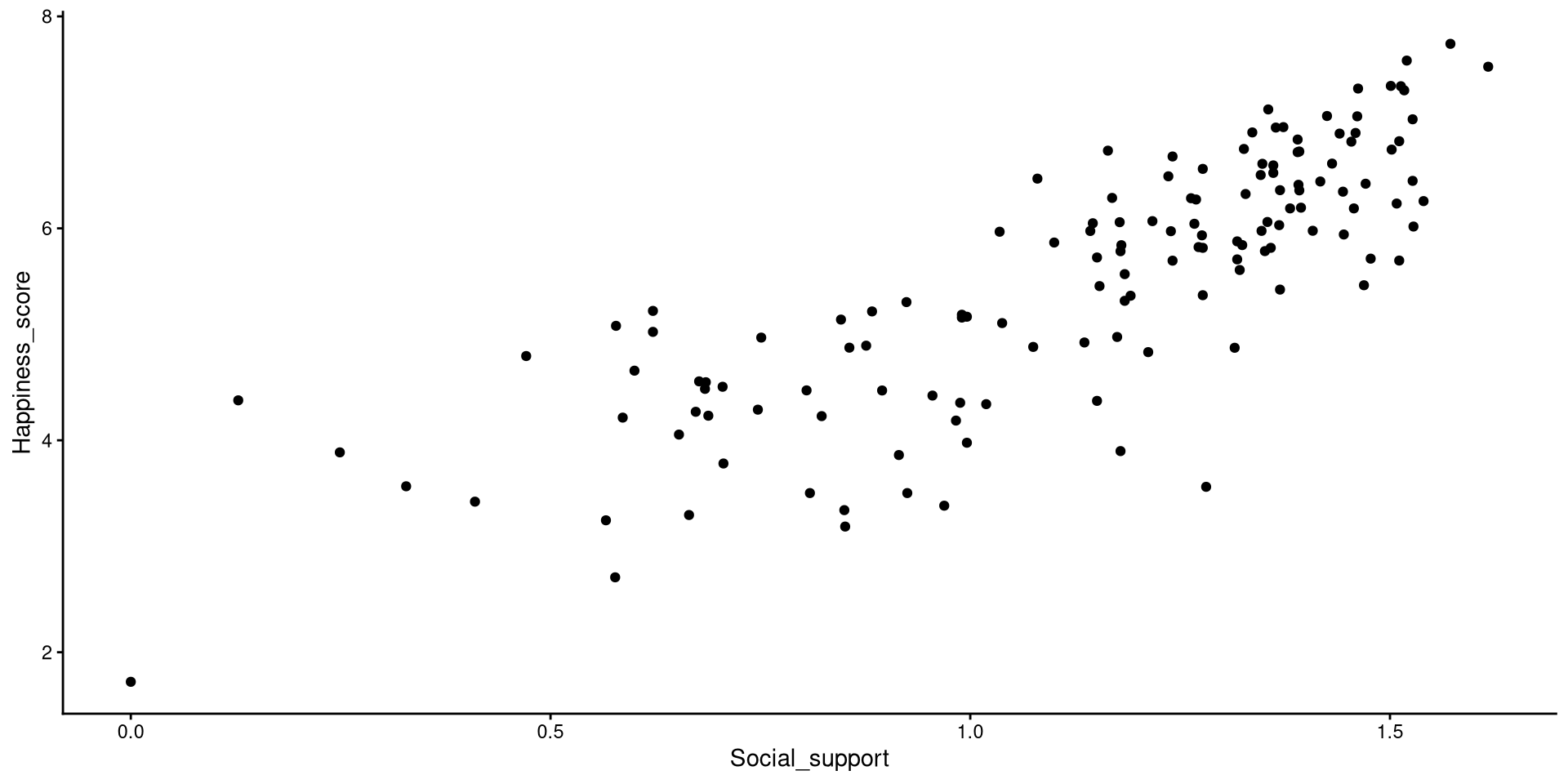
Add Regression Line
We just drew a linear regression line through the data with geom_smooth(). The relation between Social_support and Happiness_score is strongly positive.
ggplot(WH_2024,
aes(x = Social_support,
y = Happiness_score)) +
geom_point() +
theme_classic() +
geom_smooth(method = "lm",
se = FALSE)
# the argument `method = "lm"` tells `geom_smooth()` to draw a regression line. Other options exist 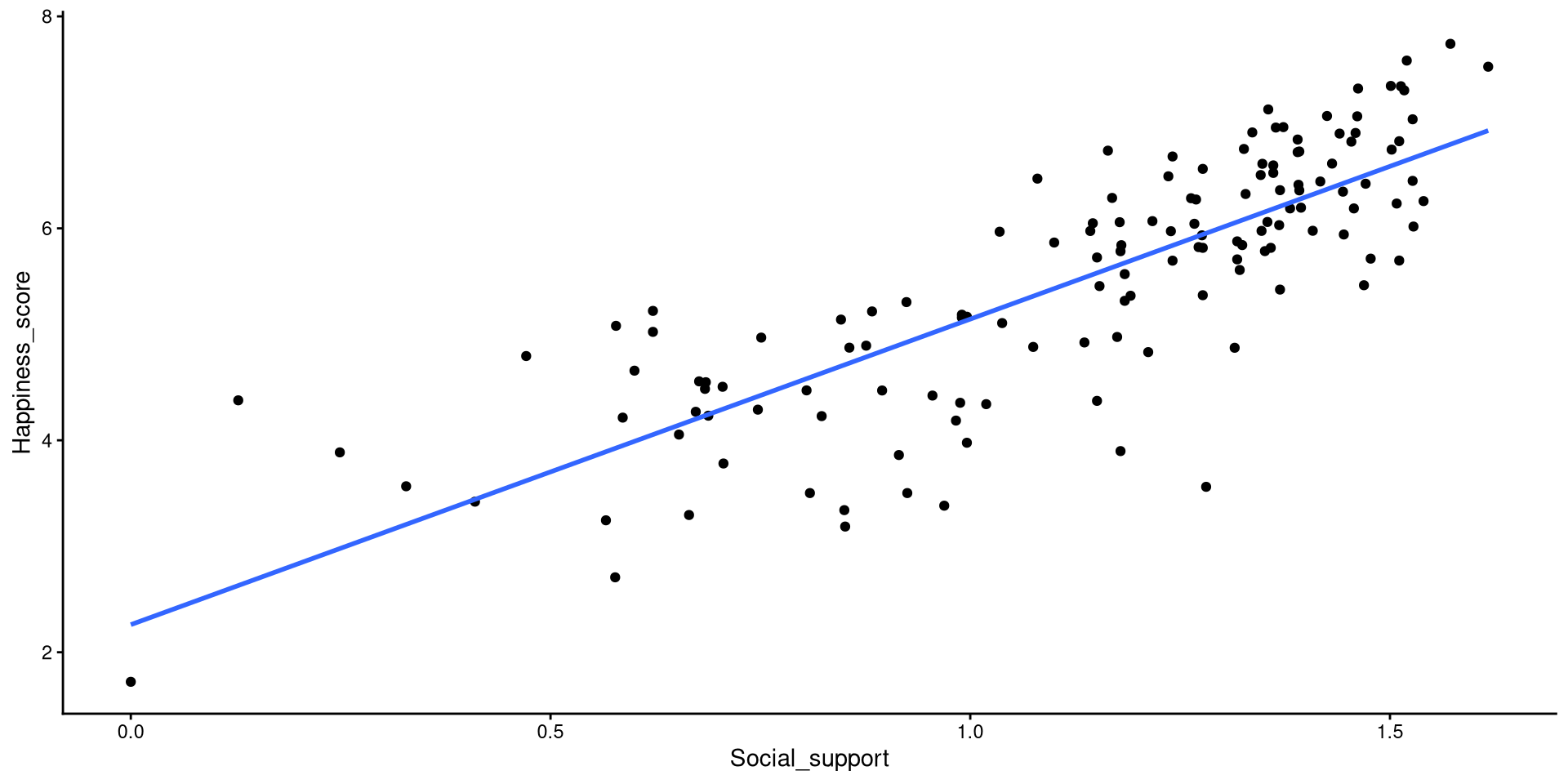
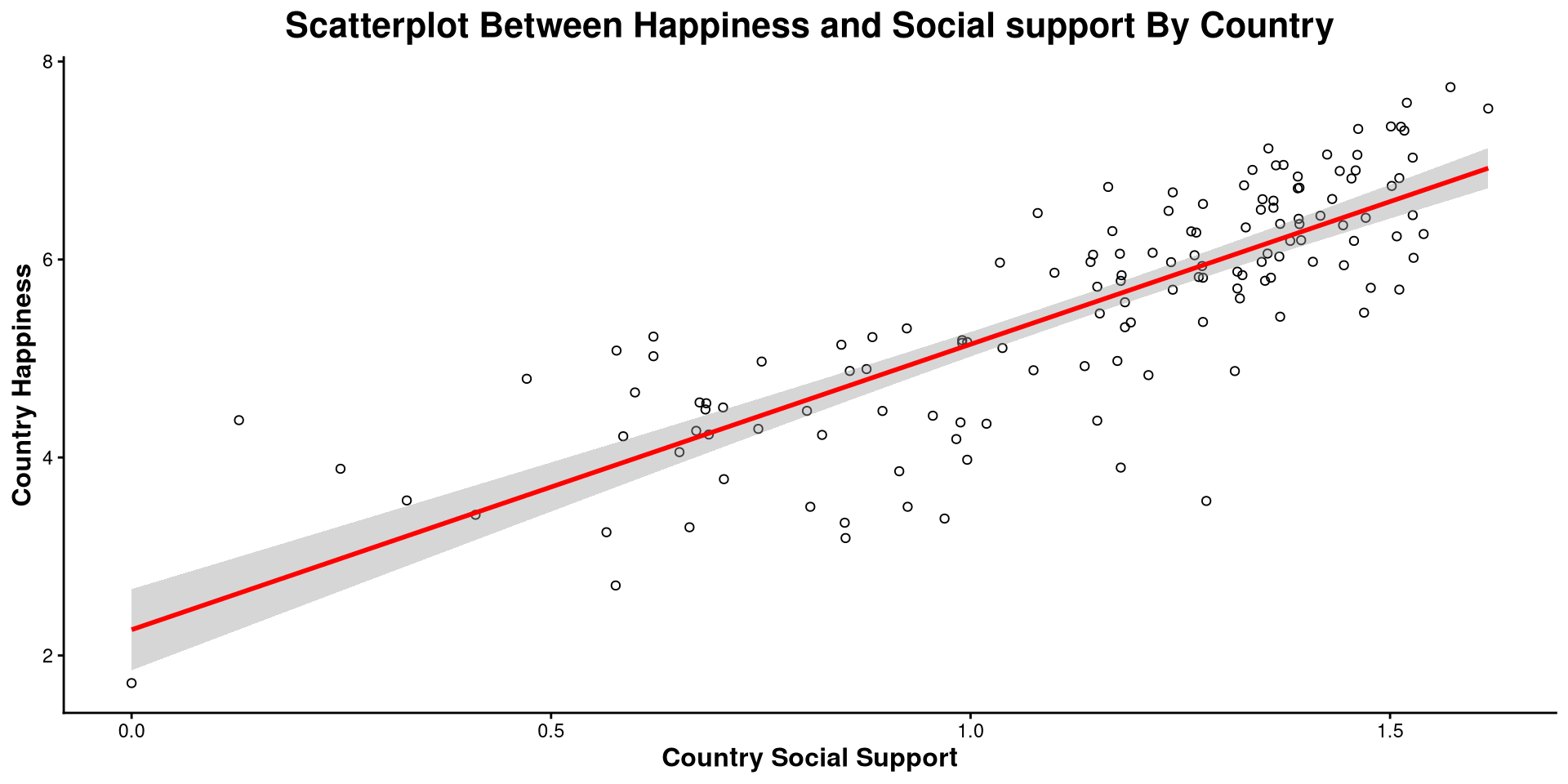
Modify Plot Elements
Here I made a bunch of changes to the plot. Spot the differences! What changes in the code resulted in what changes in the plot?
ggplot(WH_2024,
aes(x = Social_support,
y = Happiness_score)) +
geom_point(shape = 1) +
theme_classic() +
geom_smooth(method = "lm",
color = "red") +
labs(title = "Scatterplot Between Happiness and Social support By Country",
y= "Country Happiness",
x = "Country Social Support") +
theme(plot.title = element_text(hjust = 0.5, face = "bold", size = 16),
axis.title.x = element_text(face= "bold", size = 12),
axis.title.y = element_text(face= "bold", size = 12))
NOTE: The
theme() function takes in many arguments (see here) that allow you to modify font size, position of plot elements, and much more!
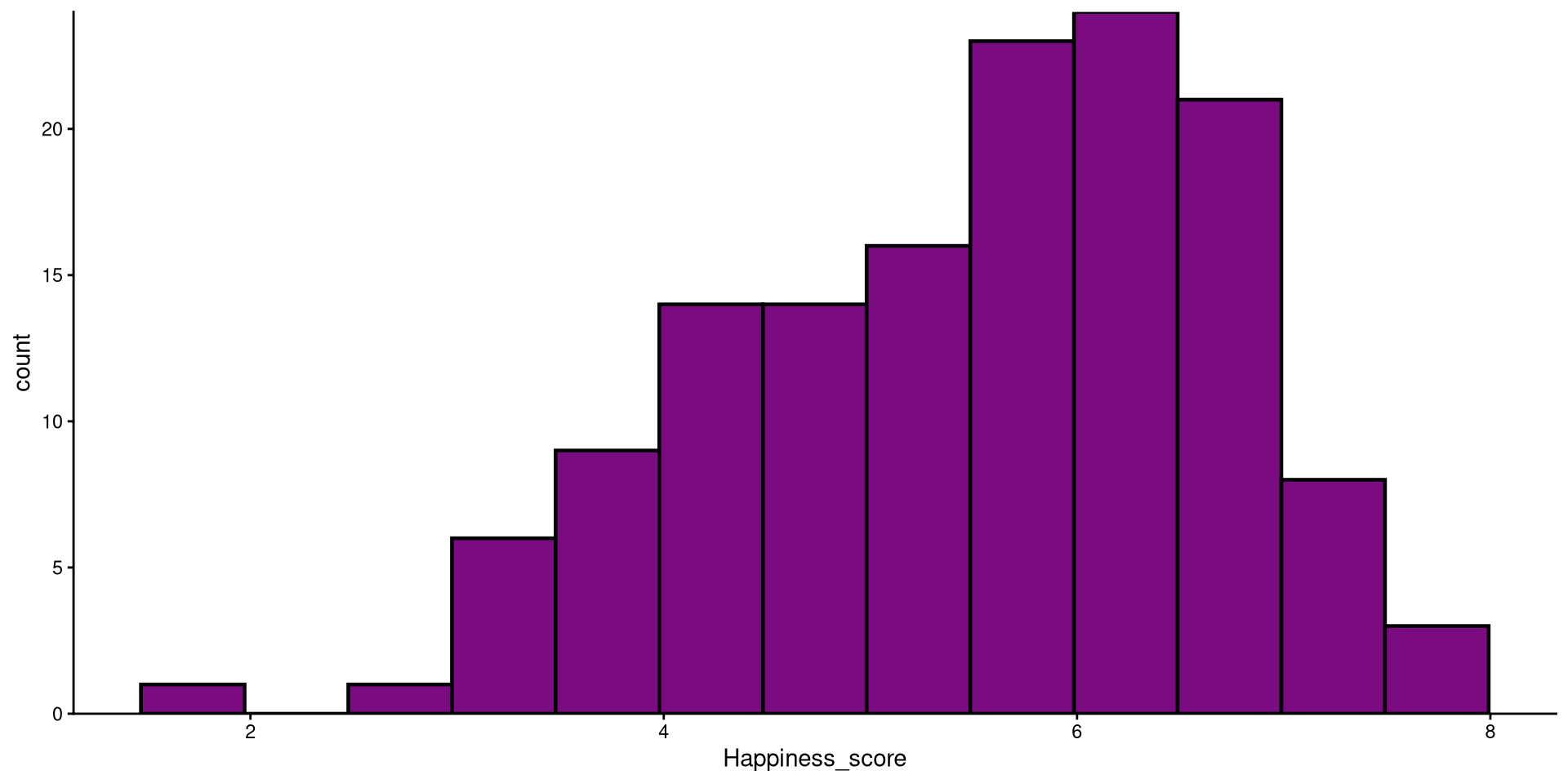
Histograms
Histograms are fairly useful for visualizing distributions of single variables. But you have to choose the number of bins appropriately.
# set theme globally
theme_set(theme_classic())
ggplot(WH_2024,
# note that we only need to give X, why?
aes(x = Happiness_score)) +
geom_histogram()bins?
the number of bins is the number of bars on the plot. the geom_histogram() function defaults to 30 bins unless you specify otherwise (we indeed have 30 bars on the plot if you count them).
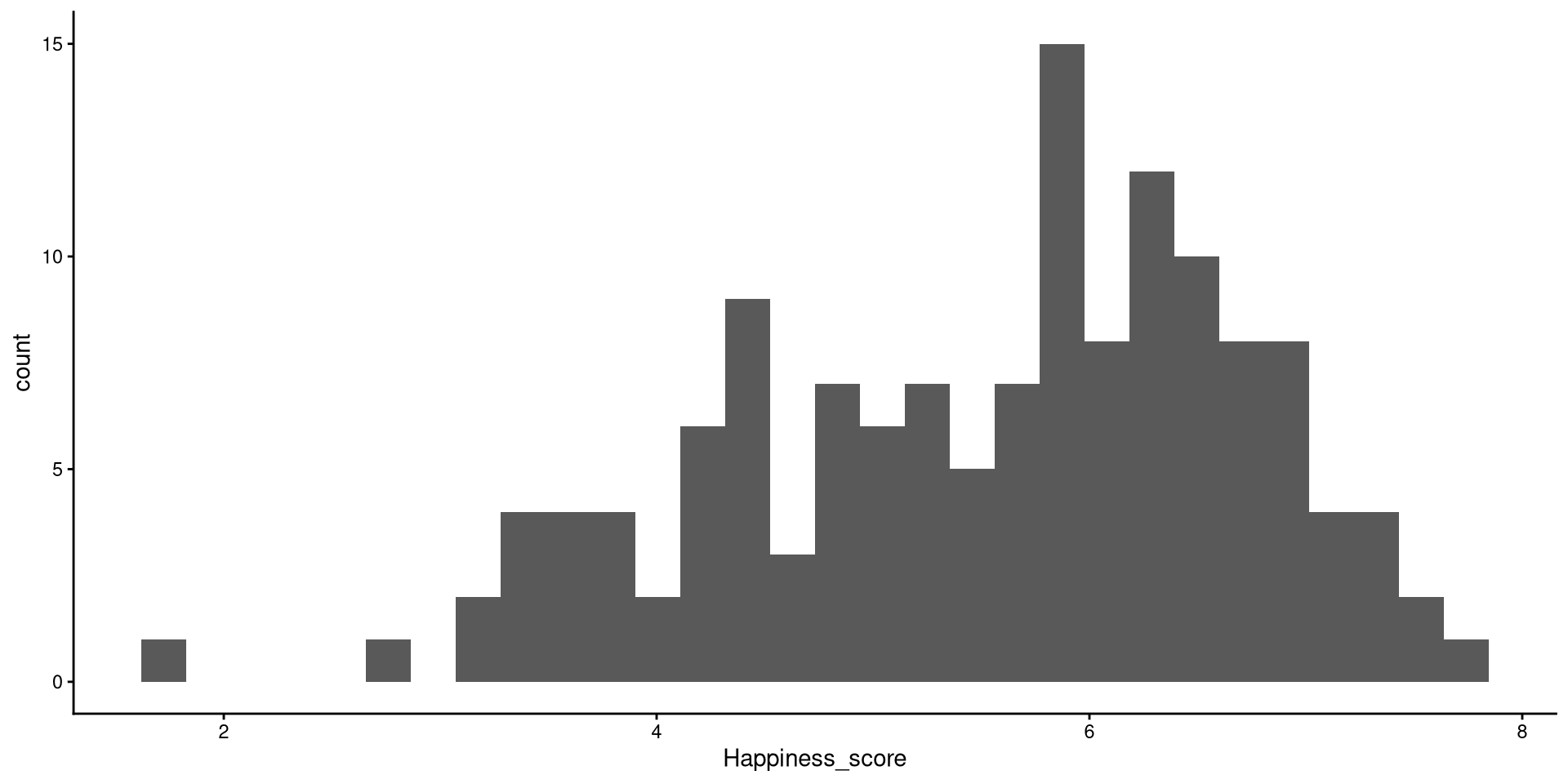
There are a bit too many bins, so it is hard to get a good sense of the distribution.
Histograms bins
Now that we have reduced the number of bins, the distribution looks more reasonable (still not the best though).
ggplot(WH_2024,
aes(x = Happiness_score)) +
geom_histogram(bins = 13) 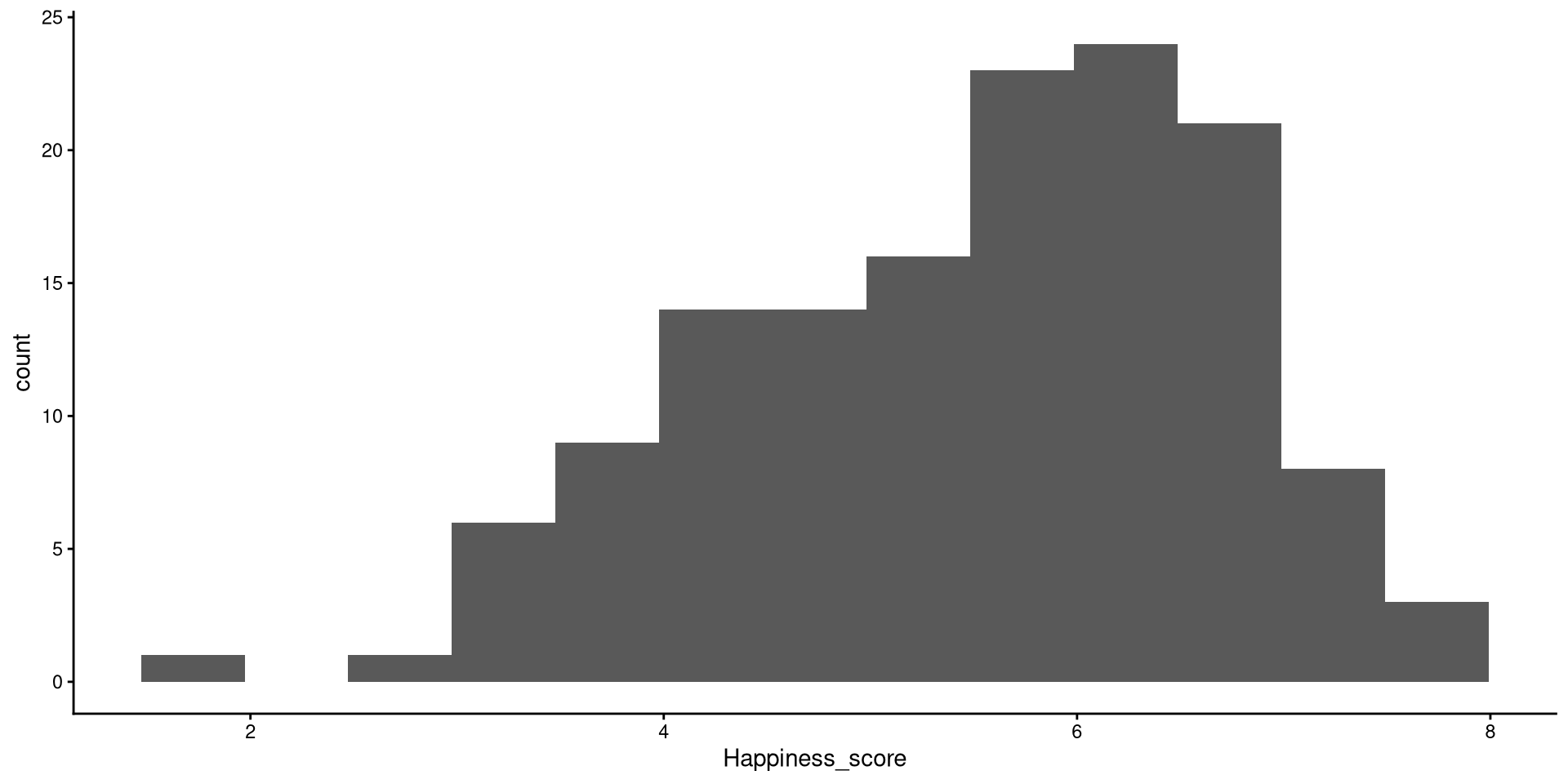
Better Looking Histogram
Here I just touched up the plot a bit. Notice the scale_y_continuous(expand = c(0,0)) function. Try running the plot without it and see if you notice the difference!
ggplot(WH_2024,
aes(x = Happiness_score)) +
geom_histogram(bins = 13,
color = "black",
linewidth = .8,
fill = "#7a0b80") +
scale_y_continuous(expand = c(0,0))HEX color codes
The “#7a0b80” is actually a color. R supports HEX color codes, which are codes that can represent just about all possible colors. There are many online color pickers (see here for example) that will let you select a color and provide the corresponding HEX color code.
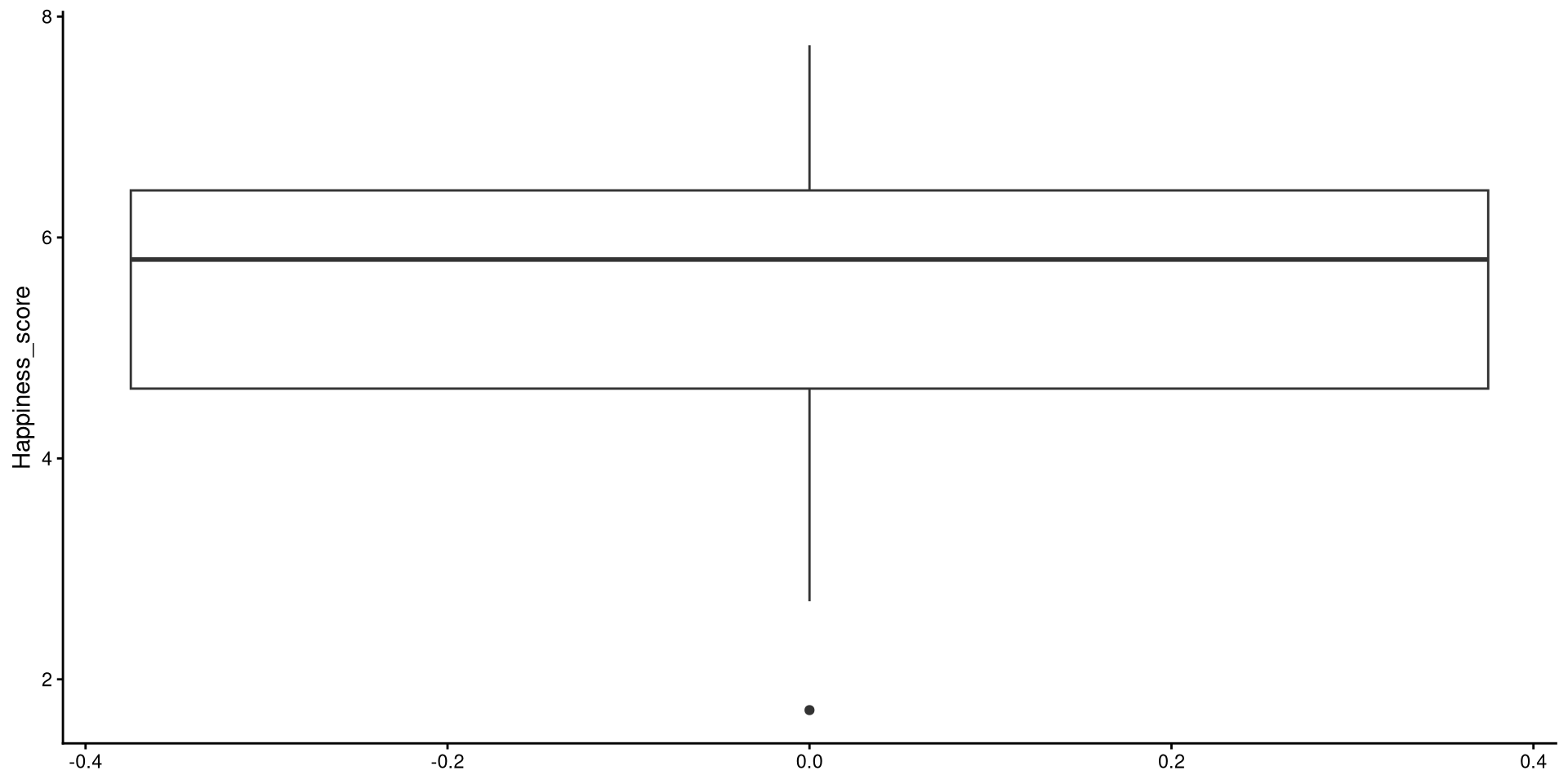
Boxplots
Box-plots very useful to get a sense of the variable’s variance, range, and to check for presence of outliers.
ggplot(WH_2024,
aes(y = Happiness_score)) +
geom_boxplot()Reading a Box-plot
The square represents the interquartile range, meaning that the bottom edge is the \(25^{th}\) percentile of the variable and the top edge is the \(75^{th}\) percentile of the variable. The bolded line is the median of the variable, which is not quite in the middle of the box. This suggests some degree of skew.
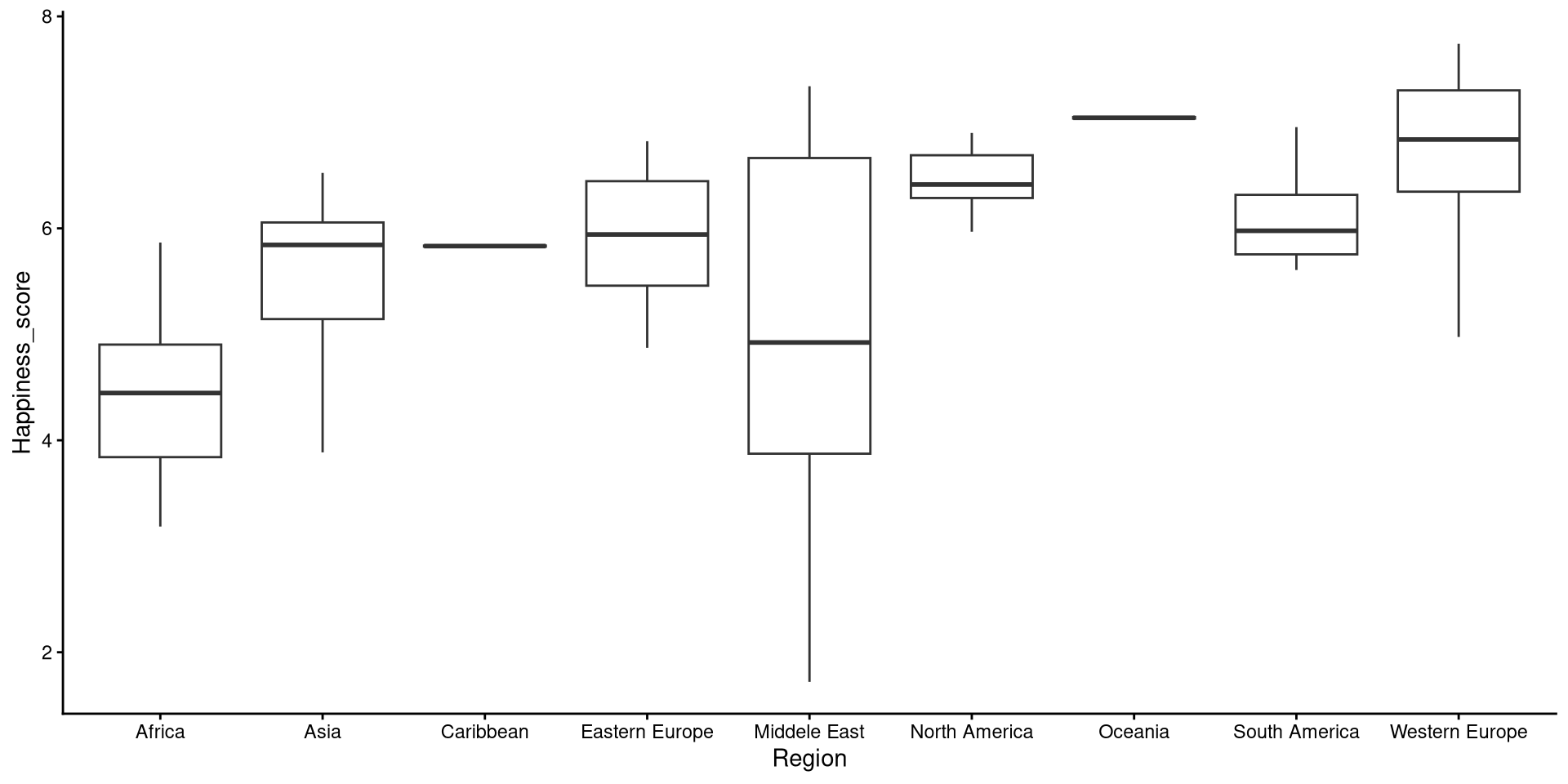
Grouped Boxplots
Boxplots also work quite well to get a graphical representation of group differences. Let’s plot Happiness_score by Region:
ggplot(WH_2024,
aes(y = Happiness_score,
x = Region)) +
geom_boxplot()So, just by looking at this boxplot we can tell that there are some noticeble differences in the distribution of Happiness_score across Region
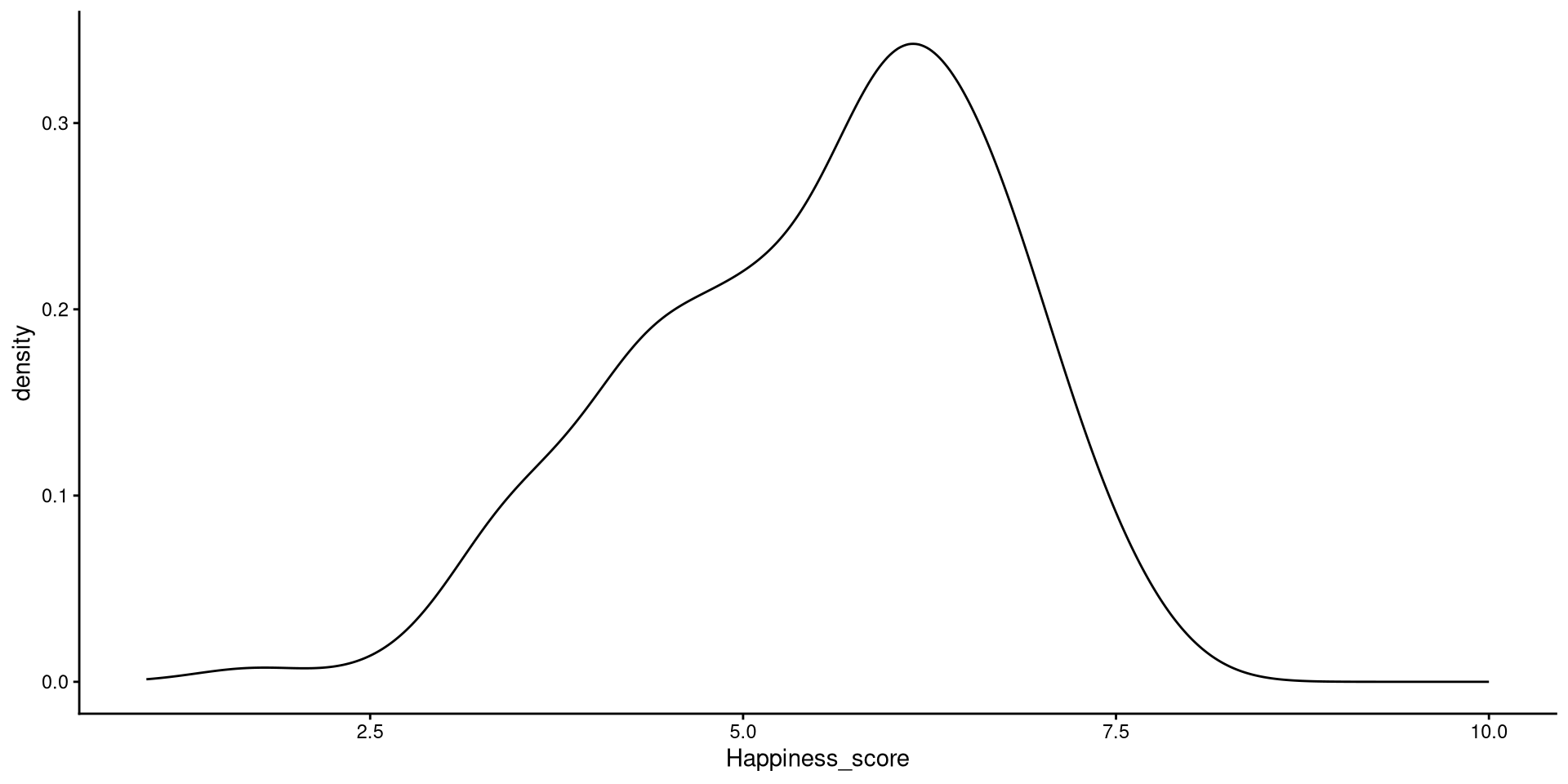
Kernel Density plots
Kernel density plots do a similar job to histograms, but I tend to prefer them over histograms.
ggplot(WH_2024,
aes(x = Happiness_score)) +
geom_density() +
xlim(1, 10)
The
xlim() function takes in 2 values that define the lower and upper bound of the x-axis (from 1 to 10).
Kernel?
The word kernel takes on widely different meanings depending on the context. In this case it is a function that estimates the probability distribution of some data (the black line in the plot) by looking at the density of observations at every point on the \(x\)-axis. Kernel estimation is often referred to as a non-parametric method.