Lab 4: t-Test
So…?
In the case of \(t\)-tests, the null hypothesis assumes some null value, \(\mu\), and checks how unlikely it is to get the sample mean value, \(\bar{x}\) if \(\mu\) is the true population mean.
This would be impossible to do unless we somehow had an estimate of the standard deviation of \(\mu\), which is exactly what \(SE\) is! We can rewrite the general \(t\) statistic formula as \(t = \frac{\bar{x} - \mu }{SE}\). Also, in most cases \(\mu = 0\), so, more often than not, the formula becomes
\[t = \frac{\bar{x}}{SE}\]
Thus, \(t\) can be roughly interpreted as how many standard deviation units \(\bar{x}\) is away from \(\mu\). The p-value will be how unlikely \(\bar{x}\), or something more extreme, is to happen if \(\mu\) is the true population mean.
Plot Code
ggplot() +
geom_function(fun = dt, args = list(df = 199), color = "#7a0b80") +
labs(x = "All Possible t statistics if H0 is true") +
xlim(-3, 3) +
geom_vline(xintercept = 2, lty = 2, col = "red") +
geom_vline(xintercept = -2, lty = 2, col = "red") +
annotate("text", x = 0, y = .2, label = paste("Values beyond the red dotted lines \n are unlikely to happen if H0 is true"), size = 5) +
scale_y_continuous(expand = c(0,0)) +
theme(axis.title.y=element_blank(),
axis.text.y=element_blank(),
axis.ticks.y=element_blank(),
axis.line.y = element_blank())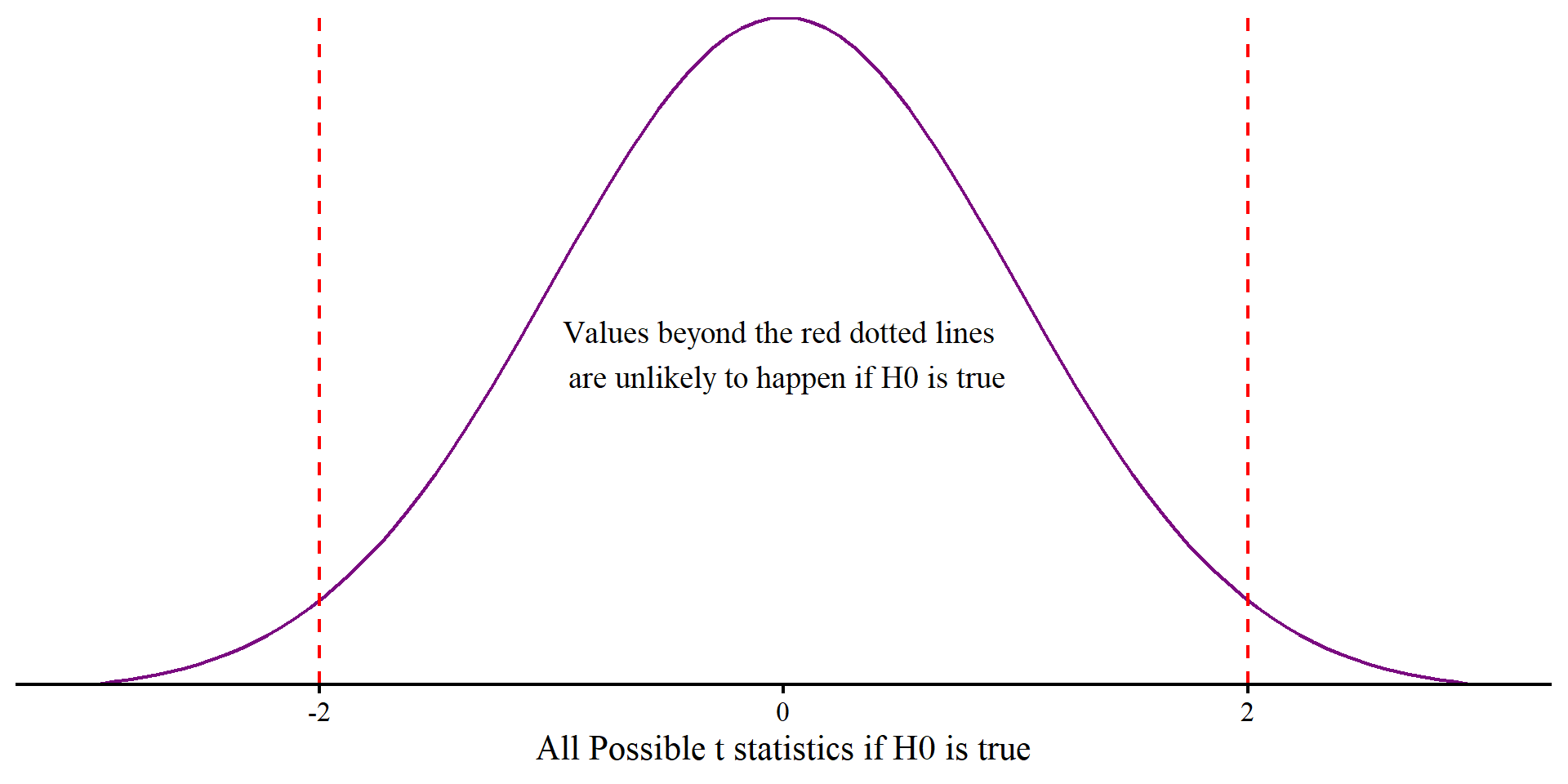
A graphical representation
The p-value represents how likely seeing \(t = 2.2\) would be if the null hypothesis, \(H_0\), is true, in which case we would expect \(t = 0\).
If \(H_0\) is true, we should see \(t = 2.2\) or more extreme in \(2.8\%\) of the samples (\(p = .028\)).
Is this enough evidence to “reject” \(H_0\)? There is no objective answer to this question (and p < .05 is not an objective answer).
Plot Code
ggplot() +
geom_function(fun = dt, args = list(df = df), color = "#7a0b80") +
labs(x = "All Possible t statistics if H0 is true") +
xlim(-3, 3) +
geom_vline(xintercept = t, lty = 2, col = "red") +
annotate("text", x = t + .5, y = .1, label = paste("Our t-value, \n", round(t, 2)), size = 5) +
scale_y_continuous(expand = c(0,0)) +
theme(axis.title.y=element_blank(),
axis.text.y=element_blank(),
axis.ticks.y=element_blank(),
axis.line.y = element_blank())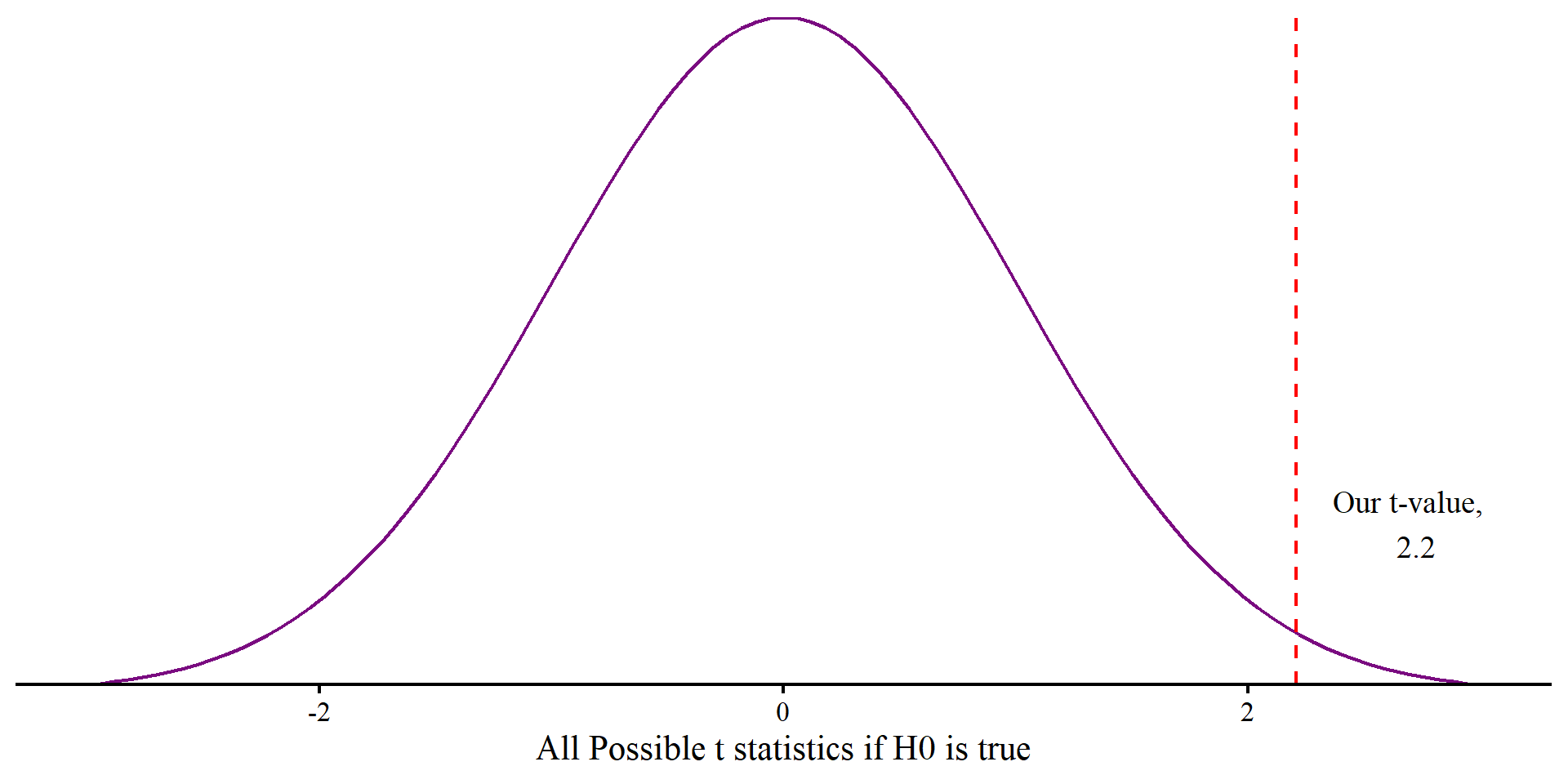
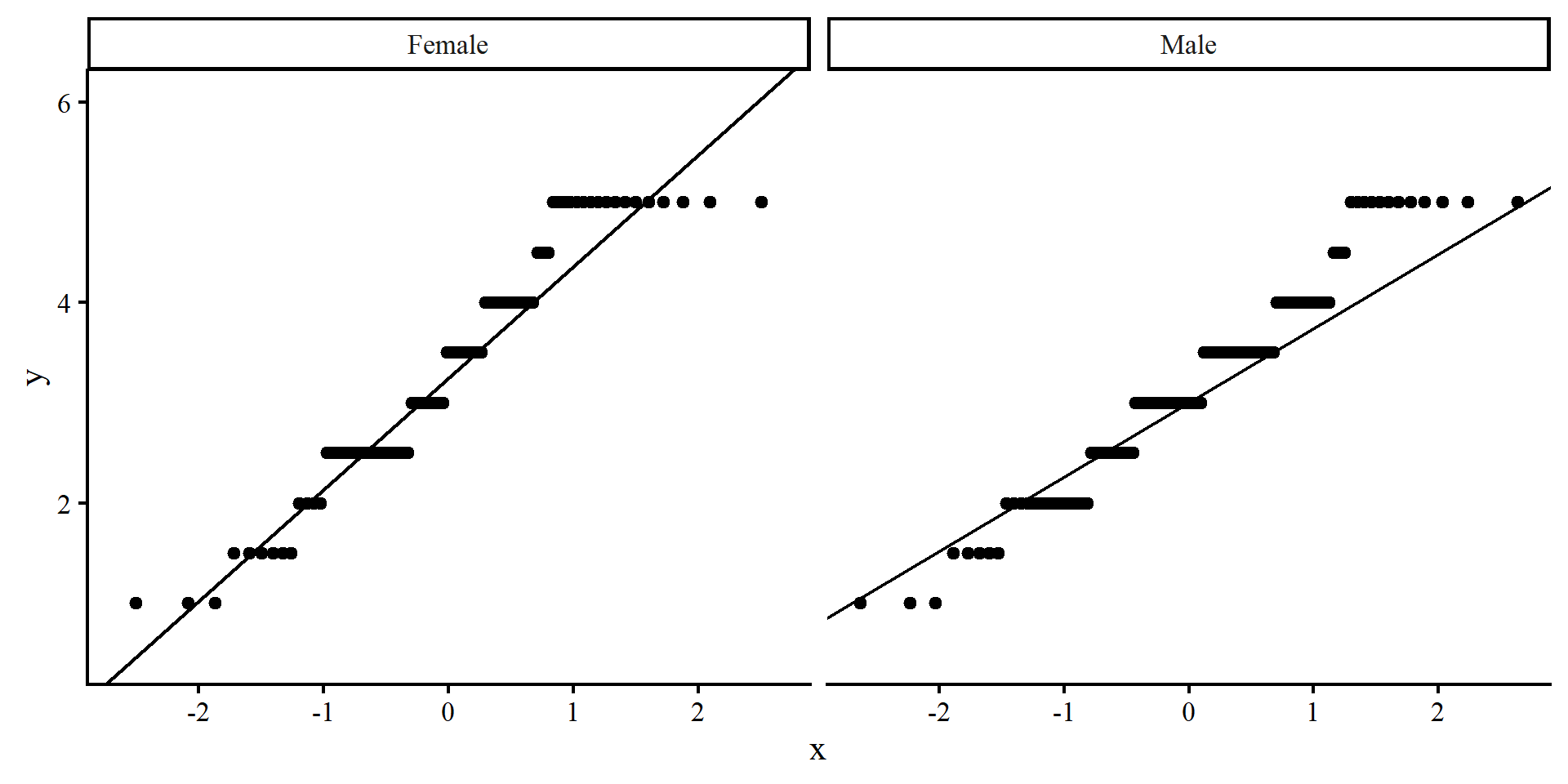
Normality of Groups: QQplot
QQplots can be good to evaluate whether a variable is not normally distributed and where the deviation from normality happens along the possible values of the variable (see here for more).
ggplot(dat,
aes(sample = Overall_Rating)) +
stat_qq() +
stat_qq_line() +
# facet_wrap() will create plots for each of the levels of Gender!
facet_wrap(~ Gender)QQplots do not work too well for this data because it is not fully continuous. In general, you’d want the line to pass through all the points, or rows of points in this case. These plots don’t look the best.
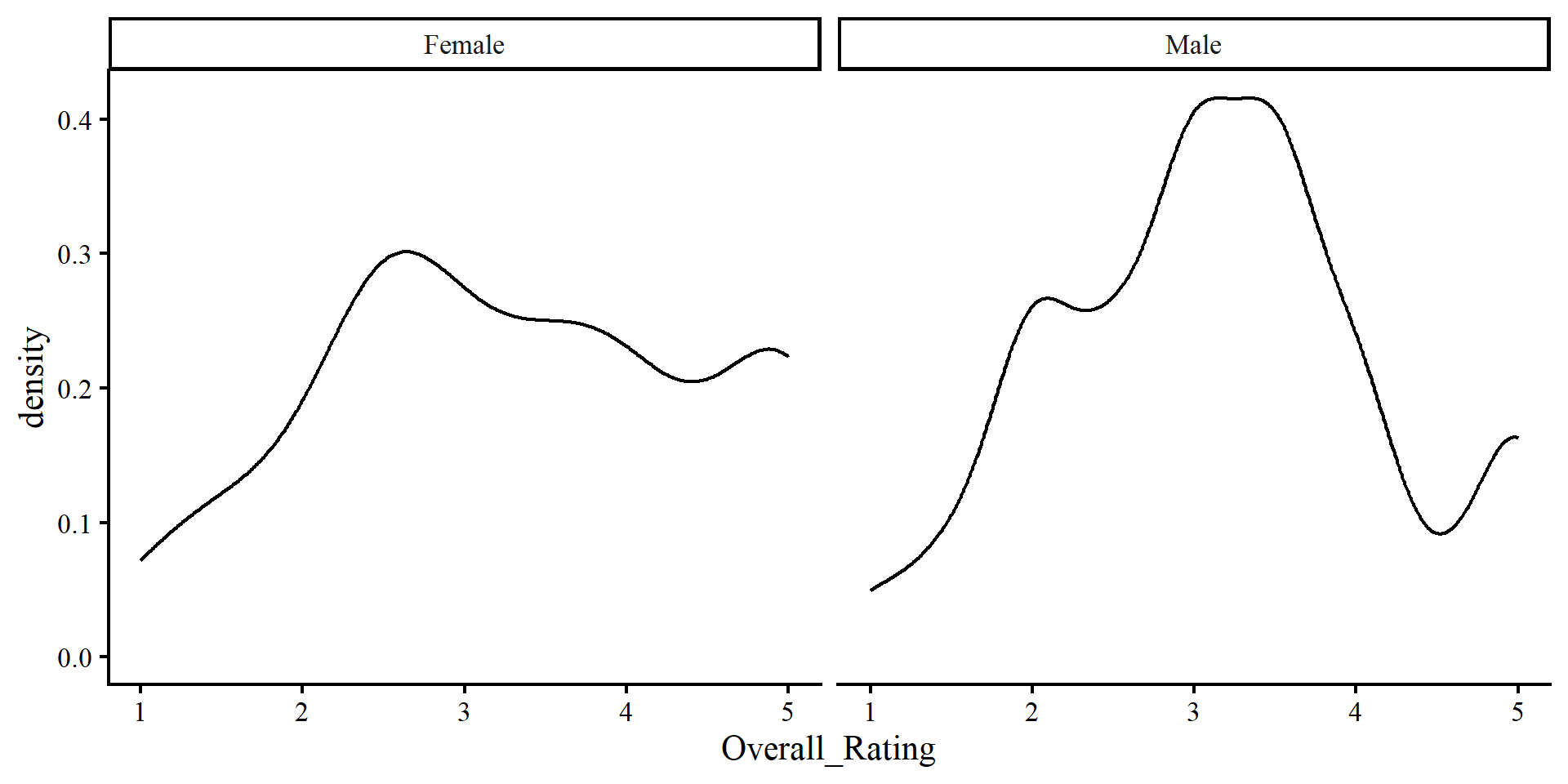
Normality of Groups: Density Plots
I personally find density plots more intuitive than QQplots.
ggplot(dat,
aes(x = Overall_Rating)) +
geom_density()+
facet_wrap(~ Gender)Here it is even more apparent that the distribution of the two groups does not resemble a normal distribution.
The two graphical methods reveal issues that descriptive statistics alone do not quite pick up on.