Lab 12: Third Variables
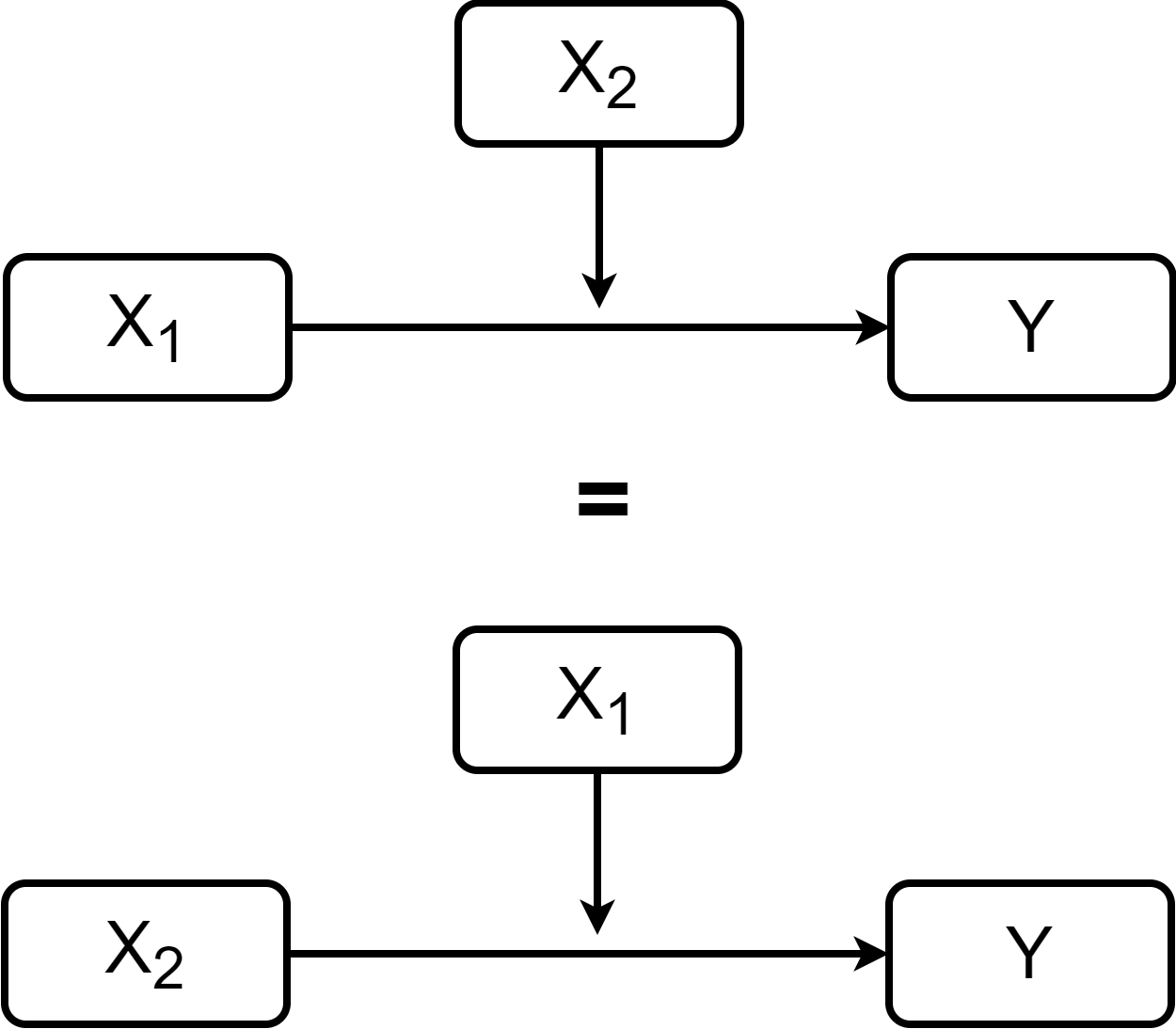
Which Variable is the moderator?
When hypothesizing interaction effects, it is useful to make a distinction between a focal predictor and a moderator. For example, if you are interesting in exploring how race (\(X_2\)) affects the impact of cognitive behavioral therapy (CBT) (\(X_1\)) on depression (\(Y\)), then I would say that race is more easily understood as the moderator and CBT as the focal predictor.
Interactions are usually represented with the diagrams on the right. the variable pointing directly to \(Y\) is considered the focal predictor, while the variable pointing to the line is considered the moderator.
The two representation on the right are equivalent (the regression equation is the same). However, depending on your hypotheses it may make more practical sense to conceptualize one variables as the focal predictor and the other as the moderator.
Plotting simple slopes
We can use the interact_plot() function from the interactions to plot the simple slopes that we just calculated.
interact_plot(reg_int,
modx = "priGPA",
pred = "attend") Once again, in modx = we specify the variable that we want to treat as the moderator, and in pred = we specify the variable that we want to treat as the focal predictor.
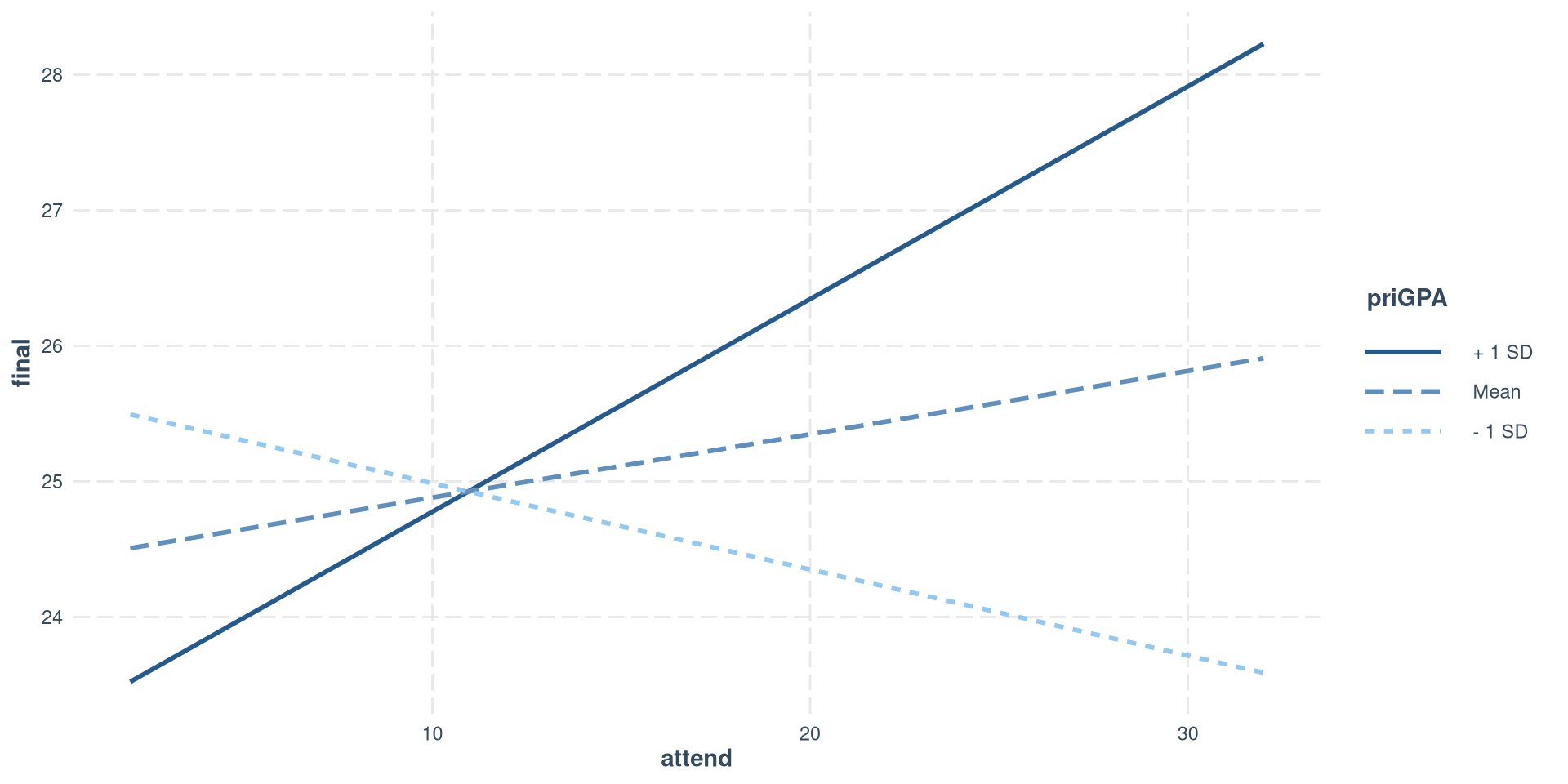
Only the slope of the regression line when priGPA is 1 SD above the mean is significantly different from 0. S, there is a positive relation between final grade and class attendance only for students who have a relatively high prior GPA.
Mediation
If we hypothesize that a casual sequence exists among our variables, we test this hypothesis with mediation analysis.
The first diagram to the right describes a regression of \(Y\) predicting \(X\). It is helpful to name the paths when talking about mediation, so \(c\) represents the slope between \(X\) and \(Y\).
If we further hypothesize that an intermediate variable, \(M\), exists such that \(X\) causes \(M\), and \(M\) causes \(Y\), we get the second diagram on the right.


Importantly, you should see that arrowheads reach two boxes in the mediation diagram. This means that the mediation diagram implies 2 separate regressions:
M ~ XY ~ X + M
This means that \(X\) can influence \(Y\) directly through the \(c'\) path, but also indirectly by influencing \(M\) through the \(a\) path, and subsequently getting to \(X\) through the \(b\) path.
A Mediation Model
Let’s say we believe that student ACT (\(X\)) score predicts grade on the final (\(Y\)). However, we think that the relation between ACT and final is mediated by the GPA for that specific term, termgpa (\(M\)).

So the regression coefficients for the paths are:

Note that running two separate regression with lm() would give the exact same result.
This graph implies these 2 regressions:
temrgpa ~ ACTfinal ~ ACT + termgpa
we can do this all at once in lavaan:
lv_2reg <-"termgpa ~ ACT
final ~ ACT + termgpa"
lv_2reg_res <- sem(lv_2reg, dat)
FabioFun::lavaan_summary(lv_2reg_res) lhs op rhs est ci.lower ci.upper
1 termgpa ~ ACT 0.052 0.036 0.067
2 final ~ ACT 0.339 0.252 0.425
3 final ~ termgpa 2.871 2.462 3.280