Lab 12: Mediation Analysis
PSYC 7804 - Regression with Lab
Path Diagrams
Path diagrams are useful for describing mediation models, as well as hypotheses in general when many variables are involved. Here are some examples:



- This path diagram represents a regression of \(X\) predicting \(Y\). the arrow-head arriving at the \(Y\) box means that \(Y\) is the dependent variable. The arrow represents the slope between \(X\) and \(Y\), hence representing their relationship.
- This path diagram represents a multiple regression of \(X_1\) and \(X_2\) predicting \(Y\). Two arrowheads arrive at \(Y\), so that implies that there are two predictors.
- Now we have added another dependent variable. Our path diagram now implies tow separate regression models. \(Z\) is a moderator, and it moderates the relation between \(X_1\) and \(Y_2\). Thus the equation predicting \(Y_2\) will be \(Y_2 \sim X_1 + X_2 + Z + X_2 \times Z\).
Remember that every arrow in the diagram corresponds to a slope
Mediation
If we hypothesize that a casual sequence exists among our variables, we test this hypothesis with mediation analysis.
The first diagram to the right describes a regression of \(Y\) predicting \(X\). It is helpful to name the paths when talking about mediation, so \(c\) represents the slope between \(X\) and \(Y\).
If we further hypothesize that an intermediate variable, \(M\), exists such that \(X\) causes \(M\), and \(M\) causes \(Y\), we get the second diagram on the right.


Importantly, you should see that arrowheads reach two boxes in the mediation diagram. This means that the mediation diagram implies 2 separate regression models:
M ~ XY ~ X + M
This means that \(X\) can influence \(Y\) directly through the \(c'\) path, but also indirectly by influencing \(M\) through the \(a\) path, and subsequently getting to \(X\) through the \(b\) path.
Direct and Indirect Effects
In mediation we can decompose the slope between \(X\) and \(Y\) into direct and indirect effect:


Total effect: \(c\)
the \(c\) path is the effect of \(X\) on \(Y\) when \(M\) is not accounted for.
Direct effect: \(c'\)
the \(c'\) (reads “c prime”) path is the effect of \(X\) on \(Y\) when \(M\) is accounted for.
Indirect effect: \(a \times b\)
\(a \times b\) represents the change in the effect of \(X\) on \(Y\) when \(M\) is accounted for. That is, how much \(Y\) is influenced by \(X\) indirectly through \(M\). (\(a \times b = c - c'\))
Mediation “By hand”
We can check that the math works out by running separate regressions. Let’s say that we think that
feeling (\(M_1\)) mediates the relation between detail (\(X\)) and opinion (\(Y\)).
# Y ~ X (c path)
reg_1 <- lm(opinion ~ detail, dat)
coef(reg_1)[-1] detail
0.6507527 # M ~ X (a path)
reg_2 <- lm(feeling ~ detail, dat)
coef(reg_2)[-1] detail
0.5517051 # Y ~ X + M (c' and b path)
reg_3 <- lm(opinion ~ detail + feeling, dat)
coef(reg_3)[-1] detail feeling
0.4237407 0.4114736 We can confirm that \(c = c' + b \times a\):
.4237 + .41147*.5517[1] 0.650708Which is the regression coefficient for Y ~ X.

Multiple mediators
Let’s assume that we also want to add
impact (\(M_2\)) as a mediator. That is, we believe that detail causes both feeling and impact, which in turn jointly cause opinion. The model implies 3 regressions. (I’ll start taking out the \(\times\) for shorter equations)

\[M_1 = a_1X\]
\[Y = c'X + b_1 M_1 + b_2 M_2\]
\[M_2 = a_2X\]
Thus, we have 2 indirect effects of detail on opinion.
-
Through
feeling: \(a_1 \times b_1\) -
Through
impact: \(a_2 \times b_2\)
And the total indirect effect of detail on opinion is:
\[a_1 \times b_1 + a_2 \times b_2\]
Multiple mediators in lavaan
We can update our
lavaan model to add \(M_2\):
mod_med2 <- "opinion ~ c*detail + b1*feeling + b2*impact
feeling ~ a1*detail
impact ~ a2*detail
indirect1 := a1*b1
indirect2 := a2*b2
total := c + a1*b1 + a2*b2"
lav_med2 <- sem(mod_med2, dat, se = "boot", bootstrap = 2000,
parallel ="snow", ncpus = 4)
lav_summary(lav_med2) lhs op rhs label est ci.lower ci.upper
1 opinion ~ detail c 0.421 0.269 0.581
2 opinion ~ feeling b1 0.410 0.243 0.571
3 opinion ~ impact b2 0.006 -0.146 0.173
4 feeling ~ detail a1 0.552 0.466 0.638
5 impact ~ detail a2 0.609 0.514 0.706
6 indirect1 := a1*b1 indirect1 0.226 0.128 0.328
7 indirect2 := a2*b2 indirect2 0.003 -0.086 0.106
8 total := c+a1*b1+a2*b2 total 0.651 0.548 0.757
The 2nd indirect effect, \(a_2 \times b_2\), is not significant, implying that
impact does not mediate the relation between detail and opinion.
Notice that now that we have two mediators, \(c'\) is the effect of
detail on opinion after accounting for both feeling and impact.
The total indirect effect, \(.23 + .01 = .24\), describes how much of the effect of
detail on opinion is mediated overall. You can also calculate it with total \(- c'\).
Moderated Mediation
We can add moderators to any of the paths in the model. Here we have our single mediator model, but we we hypothesize that the coefficients for the \(a\) and \(b\) paths should change depending on
gender. This model implies 2 regressions.

\[M = aX + z_1Z + a_zZX\]
\[Y = c'X + bM + z_2Z + b_zZM \]
Now, because we have a binary moderator where 0 = male and 1 = female:
Male equations: \(M = aX\) and \(Y = c'X + bM\)
We substitute \(0\) to any term with \(Z\), they just cancel out, and the indirect effect for male is simply \(a \times b\).
Female equations: \(M = aX + z_1 + a_zX\) and \(Y = c'X + bM + z_2 + b_zM\)
We substitute \(1\) to any term with \(Z\), the interaction terms are added to the the \(a\) and \(b\) paths. So, the indirect effect for female is \((a + a_z) \times (b + b_z)\).
Concluding remark: Be Creative
Path models may seem a bit complicated 😵 It is always important to not lose sight of the why we learn about these more complex statistical techniques. For me, it is so that I can really answer the questions I am interested in.
Path models, as well as tools like
lavaan, is where things start to get interesting in my opinion.
For example, we could also ask about the moderated mediation model from before:
- Was there a meaningful difference between the indirect effect for males and females?
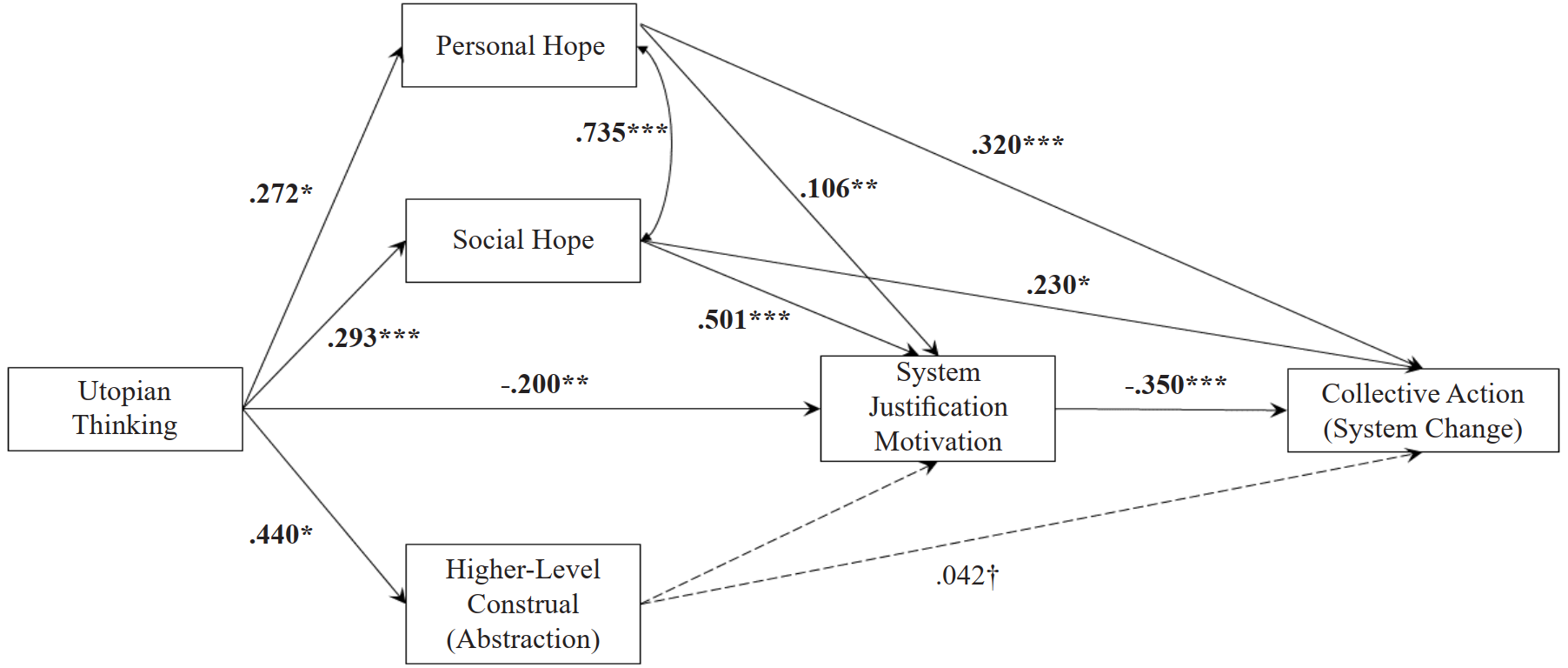
Example of an interesting path model I found here!
The value in mastering more advanced methods such as path analysis lies in the freedom that you gain as a researcher. You no longer have to fit your hypotheses and variables to some basic analysis such as a \(t\)-test of ANOVA; you can create a unique model that tests your unique and creative hypotheses 😄