Lab 5: Power
What is Power⚡?
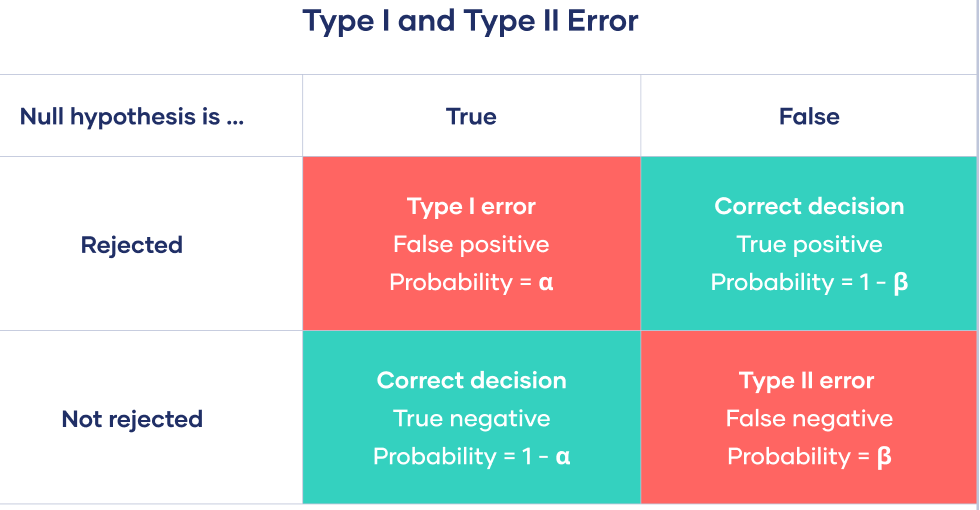
Power: Statistical power is defined as the probability of correctly rejecting the null hypothesis if \(H_0\) is false. Power is also known as 1 - Type II error rate. Type II error rate is denoted with \(\beta\), and is the probability of failing to reject a false \(H_0\).
In practice, power is used is mostly to answer the question: “how big of a sample size do I need to get a p-value lower than .05 given a certain effect size?” (pretty useless question if you ask me 😑)
The probability of making a Type I error is always the level of significance, \(\alpha\). As you know, the level of significance is almost unilaterally \(.05\). So, unless specified otherwise, \(\alpha = .05\).
On the other hand, it is common to generally look for a sample size that gives a power of \(\beta = .8\). This would mean that if \(H_0\) is false, you would reject it \(80\%\) of the times.
The Logic of the pwr Functions
All of the functions in the pwr package work in very similar fashion. They will generally include arguments representing these 4 factors that influence power:
- Effect size: could be \(d\) in the case of a \(t\)-test, \(W\) for a \(\chi^2\) test, \(R^2\) for regression…
-
Sample size: How many participants you expect to have/will need. Will usually be the
n =argument. -
Type I error rate: This is the desired \(\alpha\) level. This is always the
sig.level =argument. -
Power: The desired power. This is always the
power =argument.
pwr functions will expect to leave one of these 4 arguments empty (= NULL), and will return its value
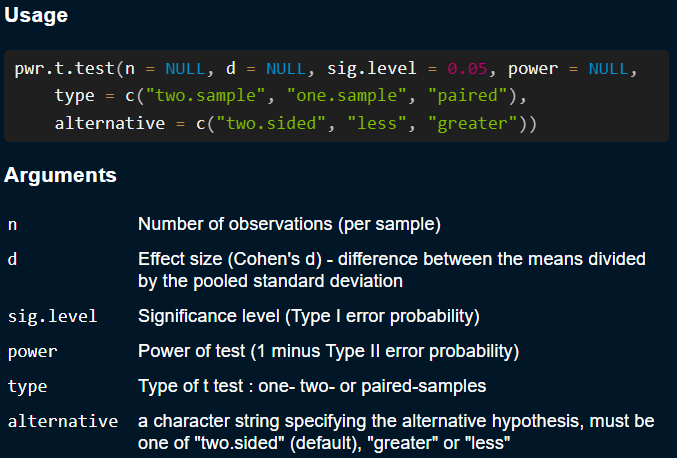
pwr.t.test() FunctionThese arguments may be named differently depending on the type of power analysis, so always check the function help menu when trying to use any of the pwr package functions.
Low Power is bad Because…
Low power is not bad because it will be hard to get \(p < .05\). Low power is bad because when you do get \(p < .05\) with low power, it is likely that:
- The effect size will be largely overestimated! (Type M error).
- The effect will be in the wrong direction! (Type S error).
You may have been “lucky” in the sense that your result was significant, but it will likely not replicate in future research. Your “lucky” result is ultimately a bad thing for the field (!!). And you will not see the results of many other people who ran the same analysis but did not get a significant p-value (publication bias!).
So, I think people care about power for the wrong reasons 🤷 Some related blog posts/manuscripts by Andrew Gelman:
