Lab 11: Logistic Regression
Plotting the regression
ggplot(dat, aes(x = prio, y = arrest)) +
geom_point() +
geom_abline(aes(intercept = coef(lin_reg)[1], slope = coef(lin_reg)[2])) +
xlim(-4, 25) + ylim(-0.2, 1.2)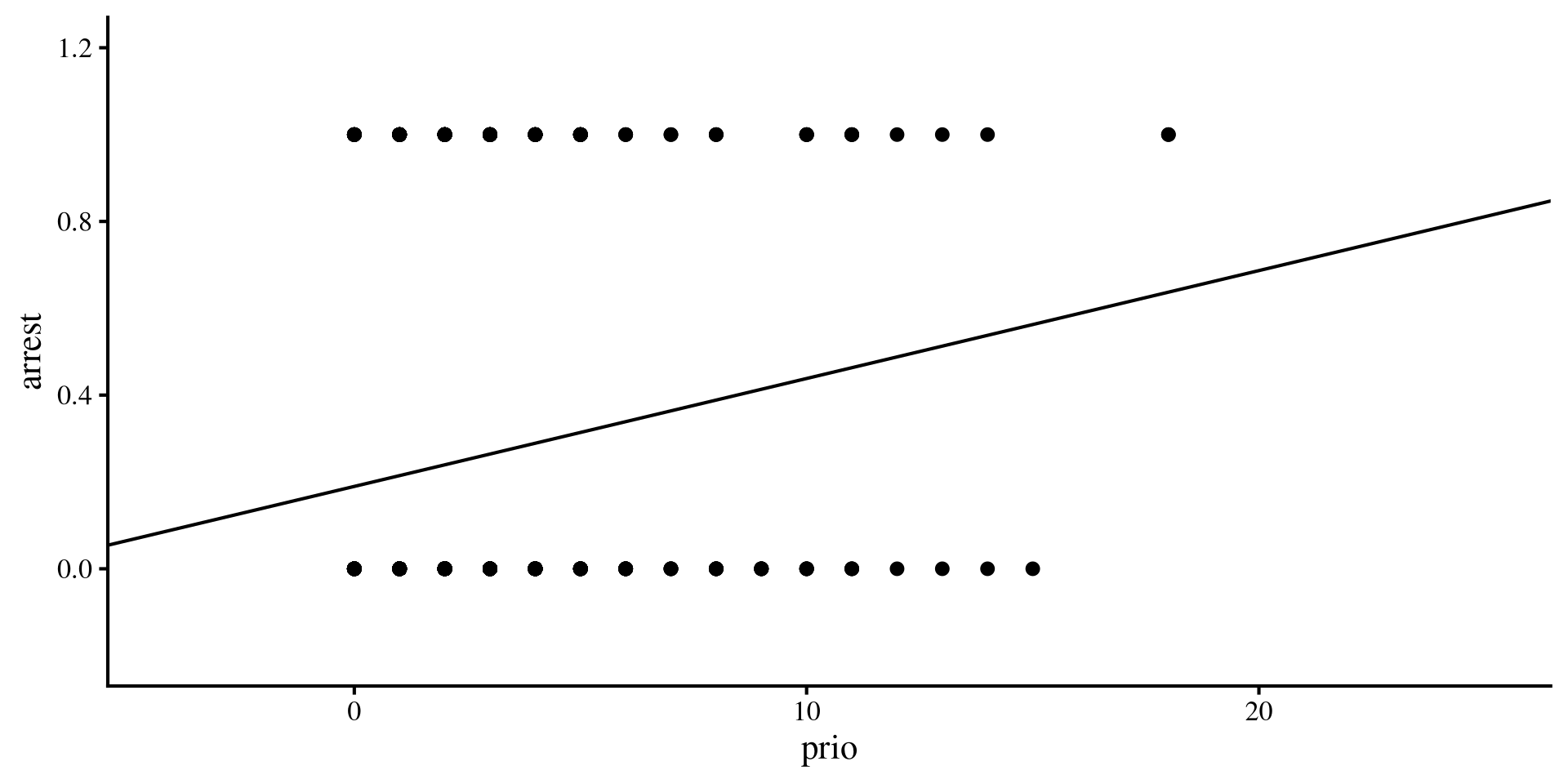
There are multiple things that should jump out to you 🧐
- It does not take a statistics expert to guess that the residuals will not be normally distributed around the regression line.
- More importantly, the regression line will eventually make predictions that are outside the possible range of
arrestwhenprioincreases beyond a certain point.
The Logistic Function
In this case, one annoying features of linear regression is that its predictions can range from \(- \infty\) to \(+ \infty\) (not good ❌). What we really want is the probability of an individual being arrested given some other variables. Probabilities can only range between \(0\) and \(1\) (good ✅).
There are functions that always give values between 0 and 1, one of them being the logistic function:
\[y = \frac{e^x}{1 + e^x}\]
As you can see the line approaches \(0\) and \(1\) when \(x\) decreases/increases, but never becomes exactly 0 or 1.
The \(e\) is Euler’s number, equals roughly \(2.718\). We can get it in R by simply typing exp(1)
exp(1)[1] 2.718282Plot Code
ggplot() +
geom_function(
fun = plogis,
col = "#7a0b80") +
labs(x = "x",
y = expression(frac(e^x, 1 + e^x))) +
xlim(-6, 6) 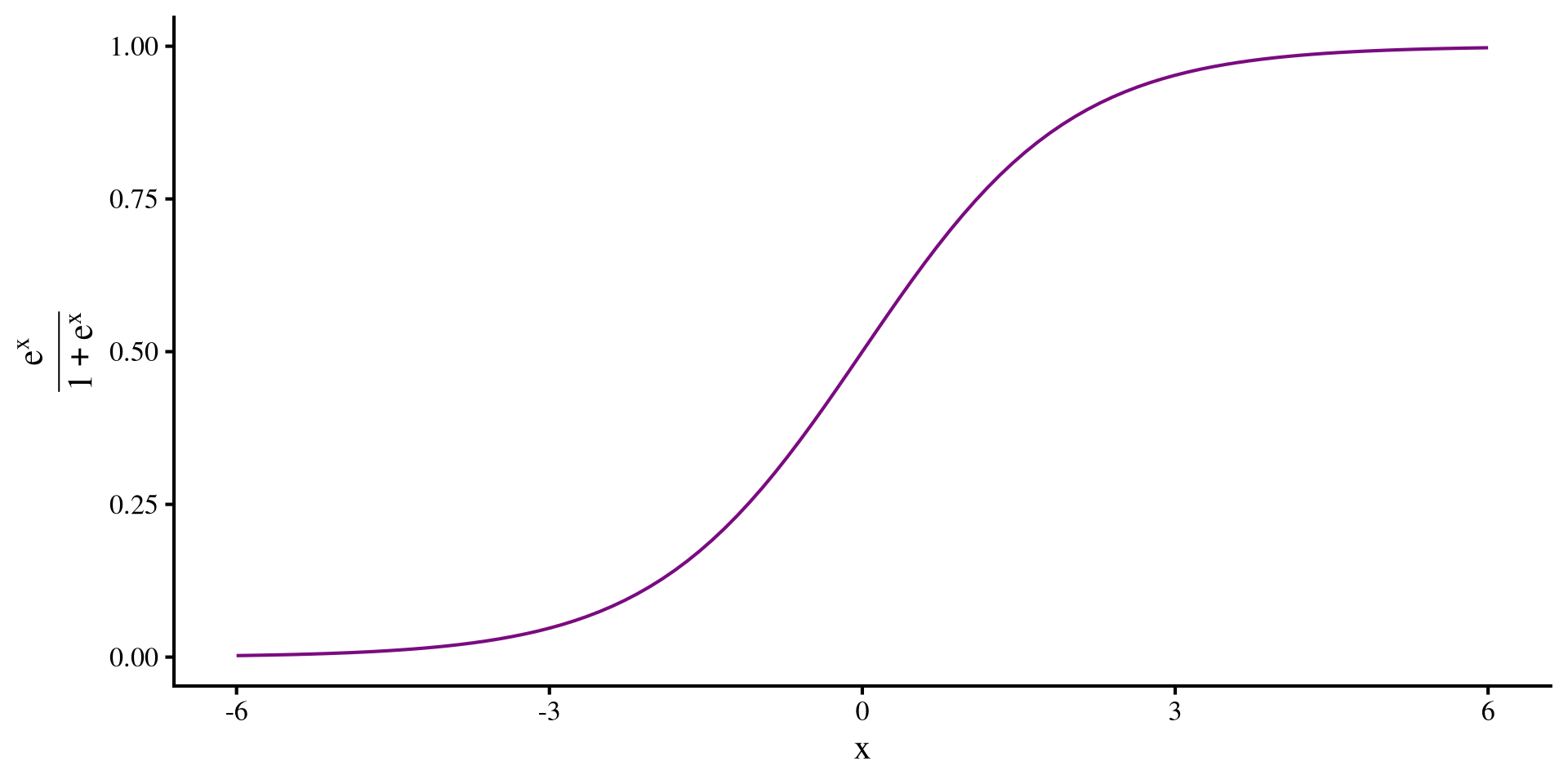
Plotting a Logistic Regression
Depending on your data, the logistic regression line may look very similar or different compared to the linear regression line. In our case they look fairly similar:
ggplot(dat, aes(x = prio, y = arrest)) +
geom_point() +
geom_smooth(method = "glm",
method.args = list(family = "binomial"),
se = FALSE)where you need to add the method.args = list(family = "binomial") part to the geom_smooth() function to tell ggplot that you want a logistic regression line.
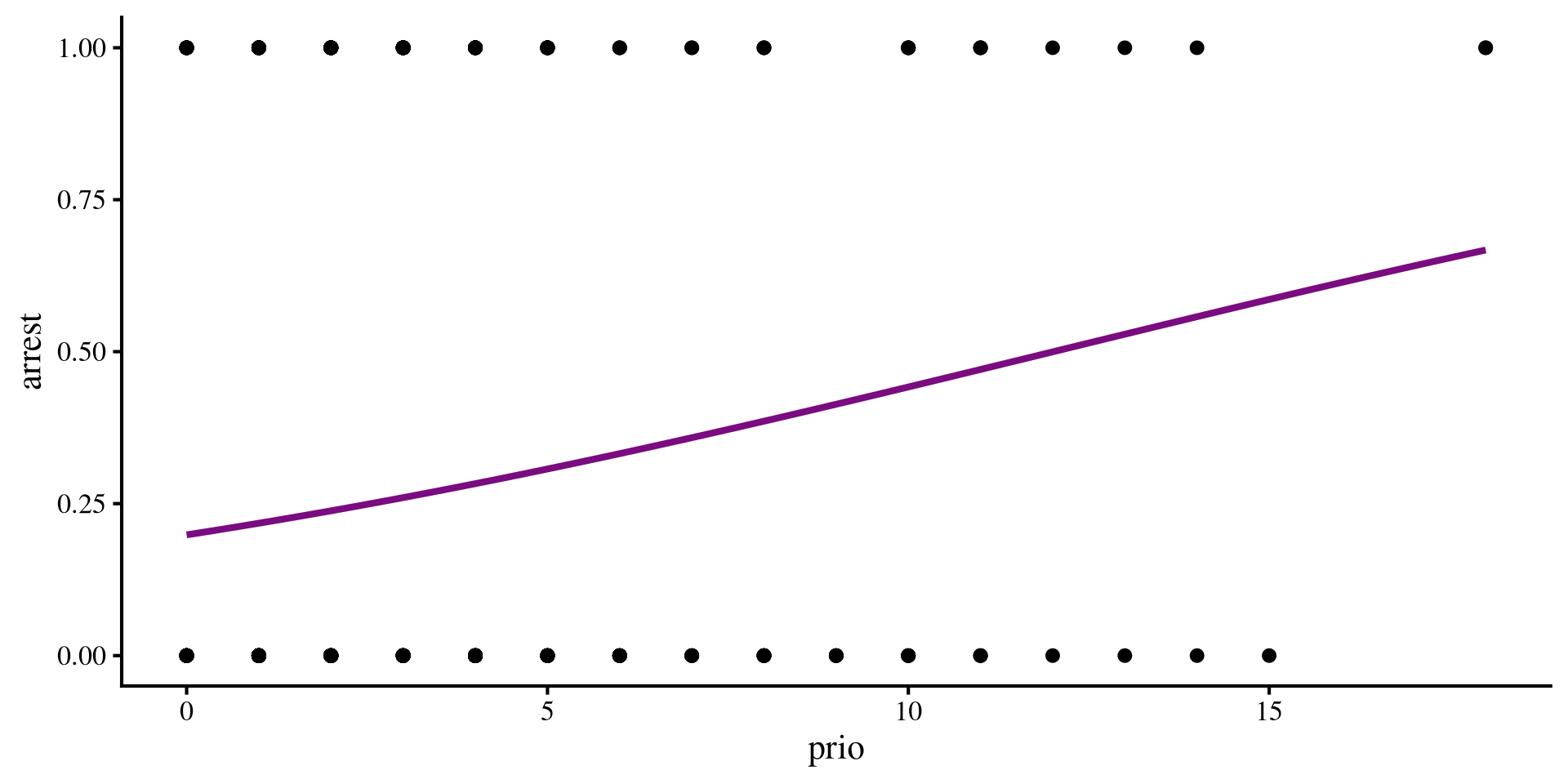
As you can see, the probability being arrested again (\(y\)-axis) increases with prior convictions. You can also see the line bending a bit, and although we don’t see it here, this line will always be between 0 and 1.
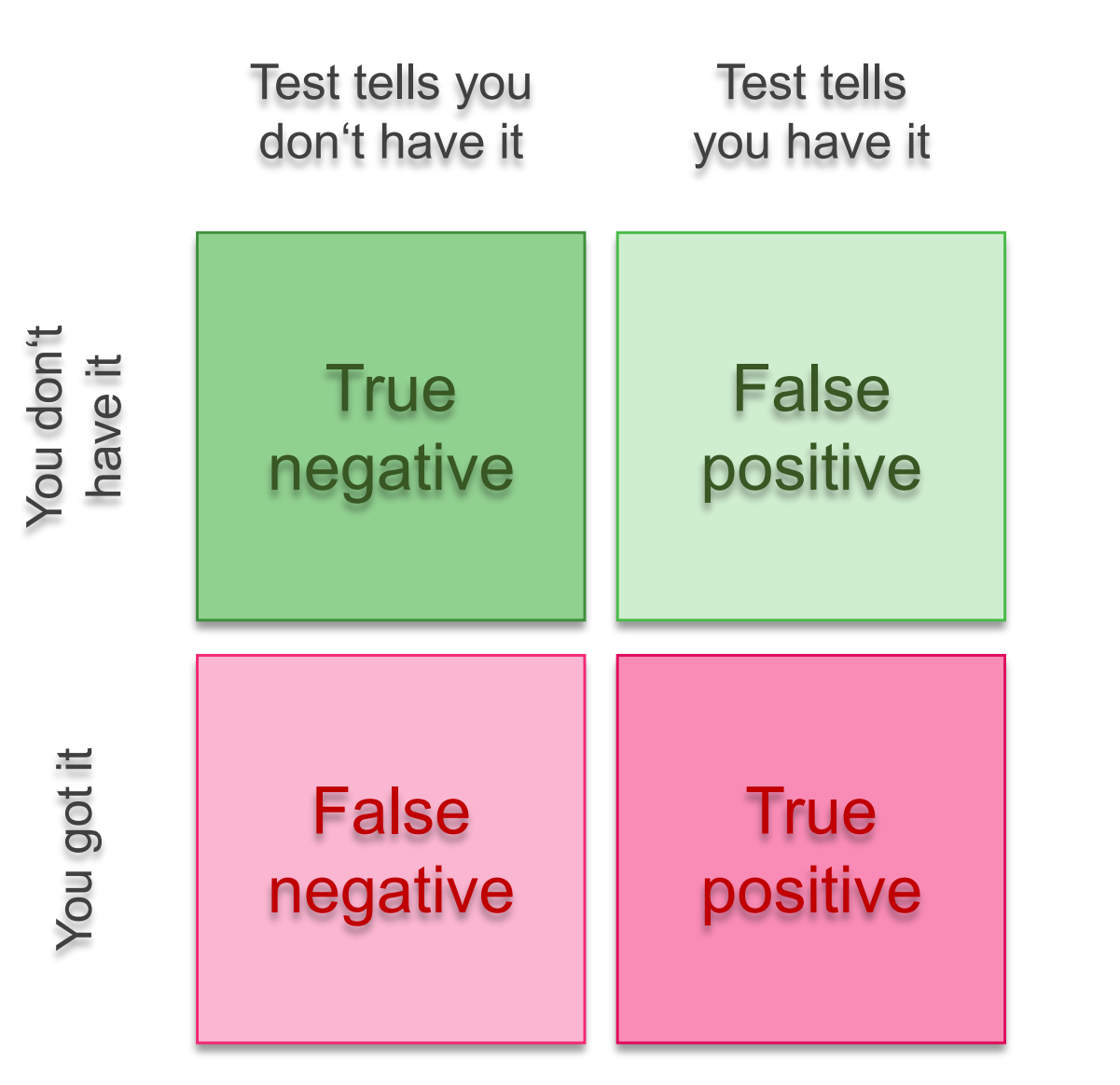
True/False Positives and Negatives
You may have realized that something is a bit off about our logistic regression predictions. To understand why classification accuracy is not a great metric, we need to talk about true/false positives and negatives.
- sensitivity: the test’s ability to correctly detect the disease in individuals who do have the disease.
\[ \mathrm{sensitivity} = \frac{\mathrm{TP}}{\mathrm{TP} + \mathrm{FN}}\]
- specificity: the test’s ability to correctly categorize individuals as healthy if they do not have the disease.
\[ \mathrm{specificity} = \frac{\mathrm{TN}}{\mathrm{TN} + \mathrm{FP}}\]